FFT 是处理信号的必备算法,但是,又该如何使用,确实值得写一下。
参考资料
概念
离散傅里叶变换(DFT)
离散傅里叶变换(discrete Fourier transform) 傅里叶分析方法是信号分析的最基本方法,傅里叶变换是傅里叶分析的核心,通过它把信号从时间域变换到频率域,进而研究信号的频谱结构和变化规律。但是它的致命缺点是:计算量太大,时间复杂度太高,当采样点数太高的时候,计算缓慢,由此出现了DFT的快速实现,即下面的快速傅里叶变换FFT。
快速傅里叶变换(FFT)
计算量更小的离散傅里叶的一种实现方法。详细细节这里不做描述。
采样频率以及采样定理
采样频率:采样频率,也称为采样速度或者采样率,定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。采样频率的倒数是采样周期或者叫作采样时间,它是采样之间的时间间隔。通俗的讲采样频率是指计算机每秒钟采集多少个信号样本。
采样定理:所谓采样定理 ,又称香农采样定理,奈奎斯特采样定理,是信息论,特别是通讯与信号处理学科中的一个重要基本结论。采样定理指出,如果信号是带限的,并且采样频率高于信号带宽的两倍,那么,原来的连续信号可以从采样样本中完全重建出来。
定理的具体表述为:
在进行模拟/数字信号的转换过程中,当采样频率fs大于信号中最高频率fmax的2倍时,即
fs>2*fmax
采样之后的数字信号完整地保留了原始信号中的信息,一般实际应用中保证采样频率为信号最高频率的2.56~4倍;采样定理又称奈奎斯特定理。
如何理解采样定理?
在对连续信号进行离散化的过程中,难免会损失很多信息,就拿一个简单地正弦波而言,如果我1秒内就选择一个点,很显然,损失的信号太多了,光着一个点我根本不知道这个正弦信号到底是什么样子的,自然也没有办法根据这一个采样点进行正弦波的还原,很明显,我采样的点越密集,那越接近原来的正弦波原始的样子,自然损失的信息越少,越方便还原正弦波。故而
采样定理说明采样频率与信号频率之间的关系,是连续信号离散化的基本依据。 它为采样率建立了一个足够的条件,该采样率允许离散采样序列从有限带宽的连续时间信号中捕获所有信息。
快速傅里叶变换
构造数据
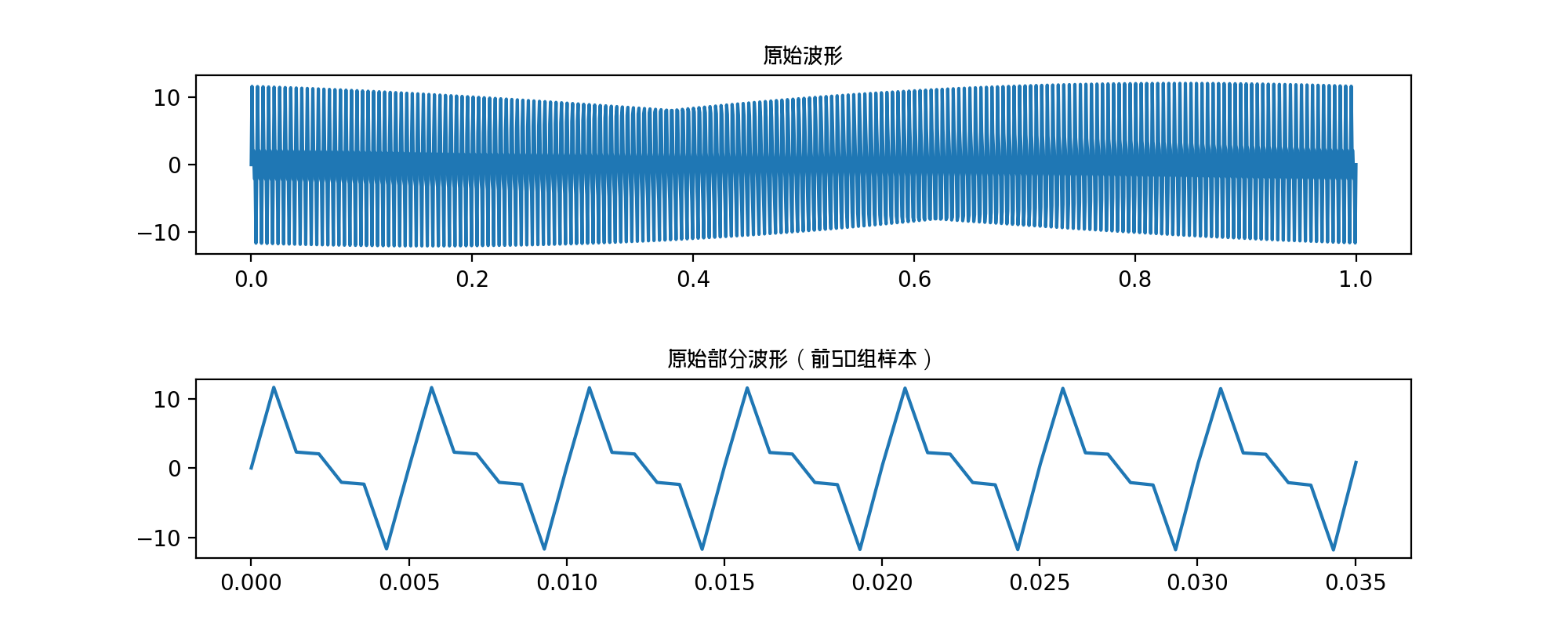
这里原始信号的三个正弦波的频率分别为,200Hz、400Hz、600Hz,最大频率为600赫兹。根据采样定理,fs至少是600赫兹的2倍,这里选择1400赫兹,即在一秒内选择1400个点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
chinese_font = FontProperties(fname='./SanJiShaHeiJianTi-2.ttf')
x = np.linspace(0, 1, 1400)
y = 7 * np.sin(2 * np.pi * 200 * x) + 5 * np.sin(2 * np.pi * 400 * x) + 3 * np.sin(2 * np.pi * 600 * x)
plt.figure(figsize=(10, 4))
plt.subplots_adjust(wspace=0.2, hspace=0.7)
plt.subplot(2, 1, 1)
plt.plot(x, y)
plt.title('原始波形', fontproperties=chinese_font)
plt.subplot(2, 1, 2)
plt.plot(x[0:50], y[0:50])
plt.title('原始部分波形(前50组样本)', fontproperties=chinese_font)
plt.show()
|
快速傅立叶变换
scipy和numpy一样,实现FFT非常简单,仅仅是一句话而已,函数接口如下:
from scipy.fftpack import fft,ifft
from numpy import fft,ifft
其中fft表示快速傅里叶变换,ifft表示其逆变换。
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
from matplotlib.font_manager import FontProperties
import numpy.fft as fft
x = np.linspace(0, 1, 1400)
y = 7 * np.sin(2 * np.pi * 200 * x) + 5 * np.sin(2 * np.pi * 400 * x) + 3 * np.sin(2 * np.pi * 600 * x)
fft_y = fft.fft(y)
print(len(fft_y))
print(fft_y[0:5])
|
然后输出相关的内容,得到
1
2
3
4
| 1400
[-4.43378667e-12+0.j 9.66210985e-05-0.04305756j
3.86508070e-04-0.08611996j 8.69732036e-04-0.12919206j
1.54641157e-03-0.17227871j]
|
我们发现以下几个特点:
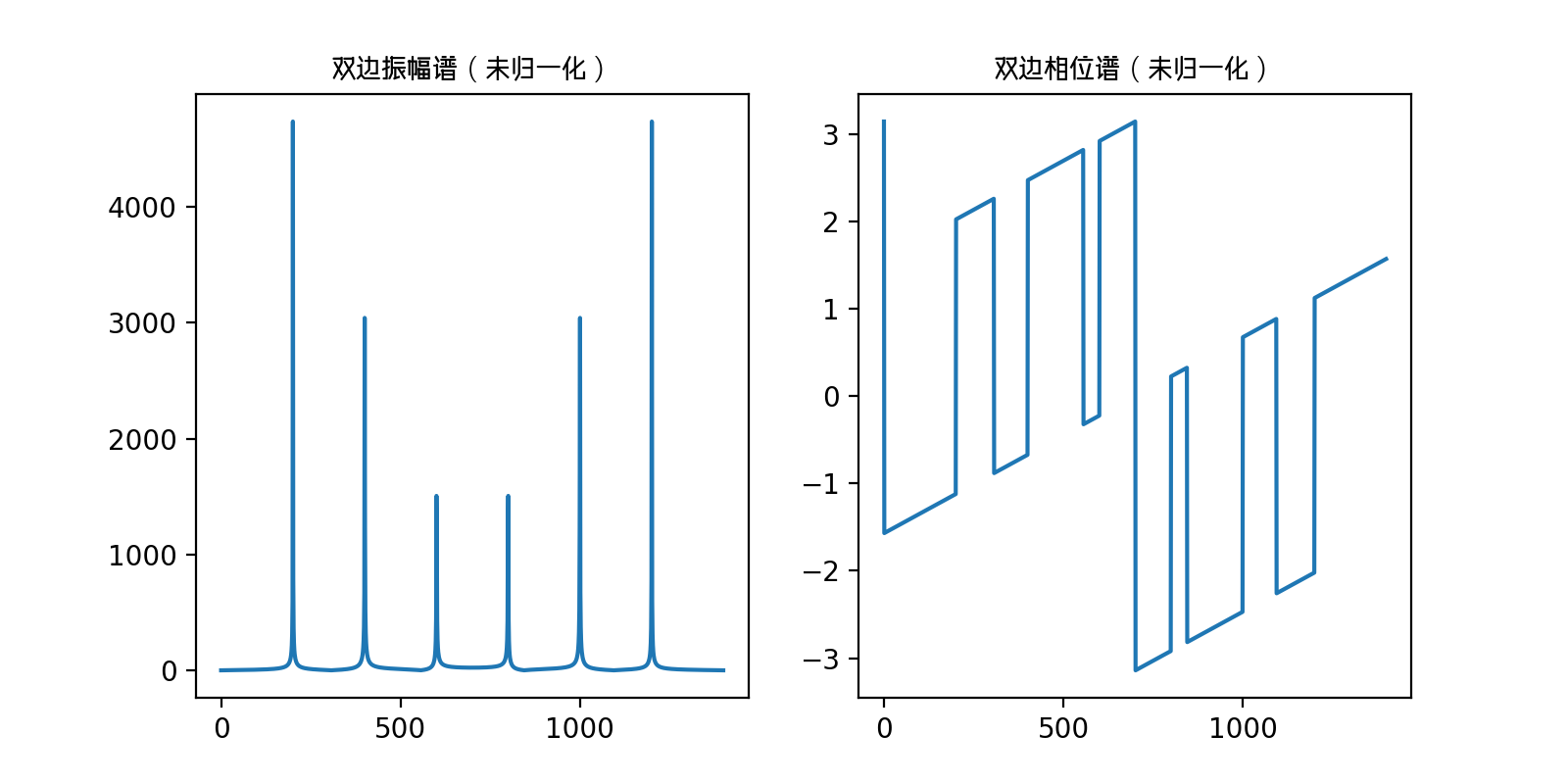
我们知道,复数a+bj在坐标系中表示为(a,b),故而复数具有模和角度,我们都知道快速傅里叶变换具有振幅谱,相位谱,它其实就是通过对快速傅里叶变换得到的复数结果进一步求出来的,
那这个直接变换后的结果是不是就是我需要的,当然是需要的,在FFT中,得到的结果是复数,
FFT得到的复数的模(即绝对值)就是对应的 振幅谱,复数所对应的角度,就是所对应的相位谱,现在可以画图了。
FFT的原始频谱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import numpy as np
from matplotlib.font_manager import FontProperties
import numpy.fft as fft
import matplotlib.pyplot as plt
chinese_font = FontProperties(fname='./SanJiShaHeiJianTi-2.ttf')
x = np.linspace(0, 1, 1400)
y = 7 * np.sin(2 * np.pi * 200 * x) + 5 * np.sin(2 * np.pi * 400 * x) + 3 * np.sin(2 * np.pi * 600 * x)
fft_y = fft.fft(y)
N = 1400
x = np.arange(N)
abs_y = np.abs(fft_y)
angle_y = np.angle(fft_y)
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.plot(x, abs_y)
plt.title('双边振幅谱(未归一化)', fontproperties=chinese_font)
plt.subplot(1, 2, 2)
plt.plot(x, angle_y)
plt.title("双边相位谱(未归一化)", fontproperties=chinese_font)
plt.show()
|
注意:我们在此处仅仅考虑“振幅谱”,不再考虑相位谱。
我们发现,振幅谱的纵坐标很大,而且具有对称性,这是怎么一回事呢?
关键:关于振幅值很大的解释以及解决办法——归一化和取一半处理
比如有一个信号如下:
Y=A1+A2*cos(2πω2+φ2)+A3*cos(2πω3+φ3)+A4*cos(2πω4+φ4)
经过FFT之后,得到的“振幅图”中,
- 第一个峰值(频率位置)的模是
A1的N倍,N为采样点,本例中为N=1400,此例中没有,因为信号没有常数项A1
- 第二个峰值(频率位置)的模是
A2的N/2倍,N为采样点,
- 第三个峰值(频率位置)的模是
A3的N/2倍,N为采样点,
- 第四个峰值(频率位置)的模是
A4的N/2倍,N为采样点,
依次下去……
考虑到数量级较大,一般进行归一化处理,既然第一个峰值是A1的N倍,那么将每一个振幅值都除以N即可.
FFT具有对称性,一般只需要用N的一半,前半部分即可。
将振幅谱进行归一化和取半处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import numpy as np
from matplotlib.font_manager import FontProperties
import numpy.fft as fft
import matplotlib.pyplot as plt
chinese_font = FontProperties(fname='./SanJiShaHeiJianTi-2.ttf')
x = np.linspace(0, 1, 1400)
y = 7 * np.sin(2 * np.pi * 200 * x) + 5 * np.sin(2 * np.pi * 400 * x) + 3 * np.sin(2 * np.pi * 600 * x)
fft_y = fft.fft(y)
N = 1400
x = np.arange(N)
abs_y = np.abs(fft_y)
angle_y = np.angle(fft_y)
plt.figure(figsize=(8, 4))
normalization_y = abs_y / N
plt.figure()
plt.plot(x, normalization_y, 'g')
plt.title('双边频谱(归一化)', fontproperties=chinese_font)
plt.show()
|

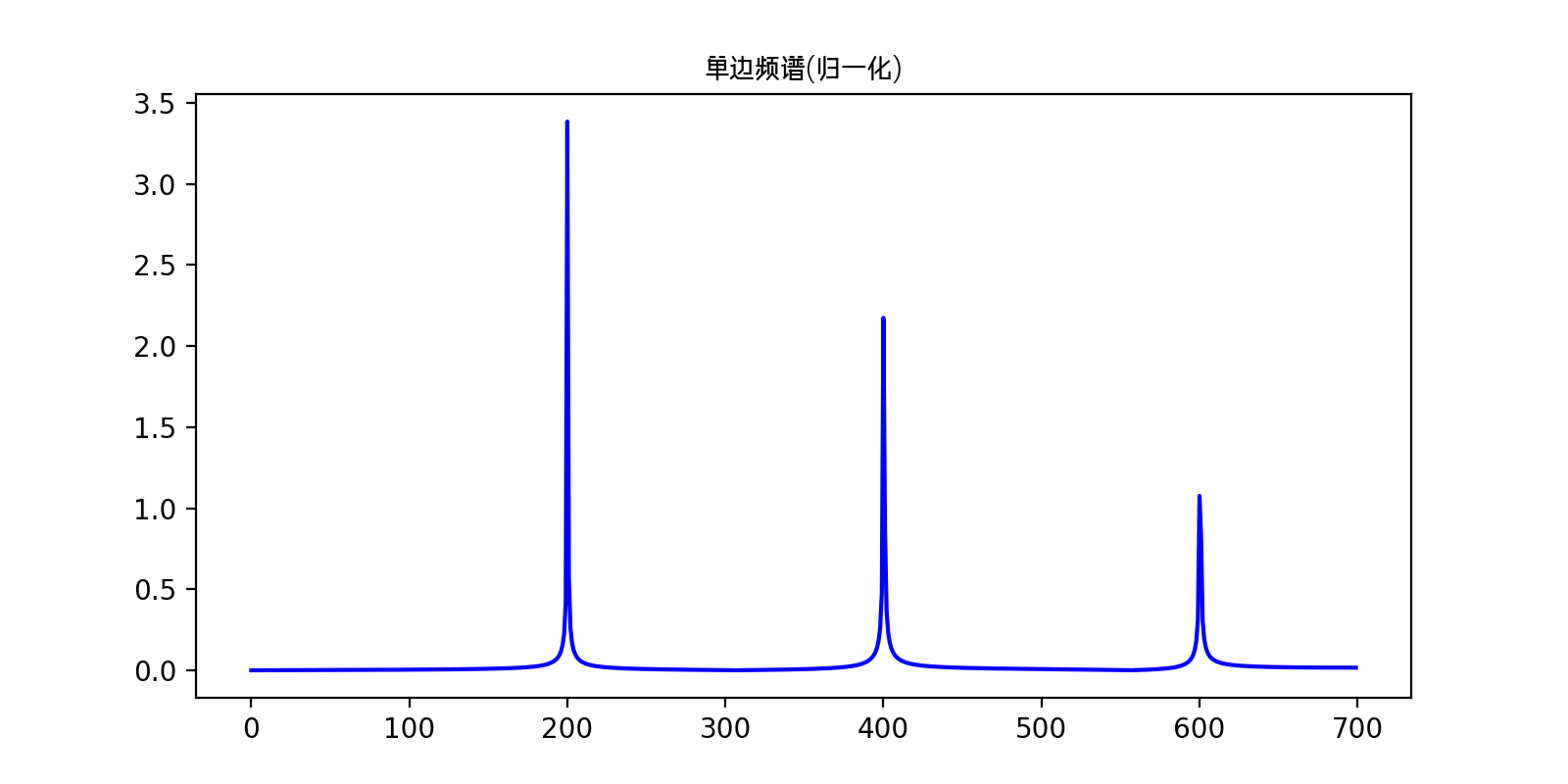
现在我们发现,振幅谱的数量级不大了,变得合理了,接下来进行取半处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import numpy as np
from matplotlib.font_manager import FontProperties
import numpy.fft as fft
import matplotlib.pyplot as plt
chinese_font = FontProperties(fname='./SanJiShaHeiJianTi-2.ttf')
x = np.linspace(0, 1, 1400)
y = 7 * np.sin(2 * np.pi * 200 * x) + 5 * np.sin(2 * np.pi * 400 * x) + 3 * np.sin(2 * np.pi * 600 * x)
fft_y = fft.fft(y)
N = 1400
x = np.arange(N)
abs_y = np.abs(fft_y)
angle_y = np.angle(fft_y)
plt.figure(figsize=(8, 4))
normalization_y = abs_y / N
half_x = x[range(int(N / 2))]
normalization_half_y = normalization_y[range(int(N / 2))]
plt.plot(half_x, normalization_half_y, 'b')
plt.title('单边频谱(归一化)', fontproperties=chinese_font)
plt.show()
|