这里介绍 eosvoter 的后端系统。
思维导图如下:
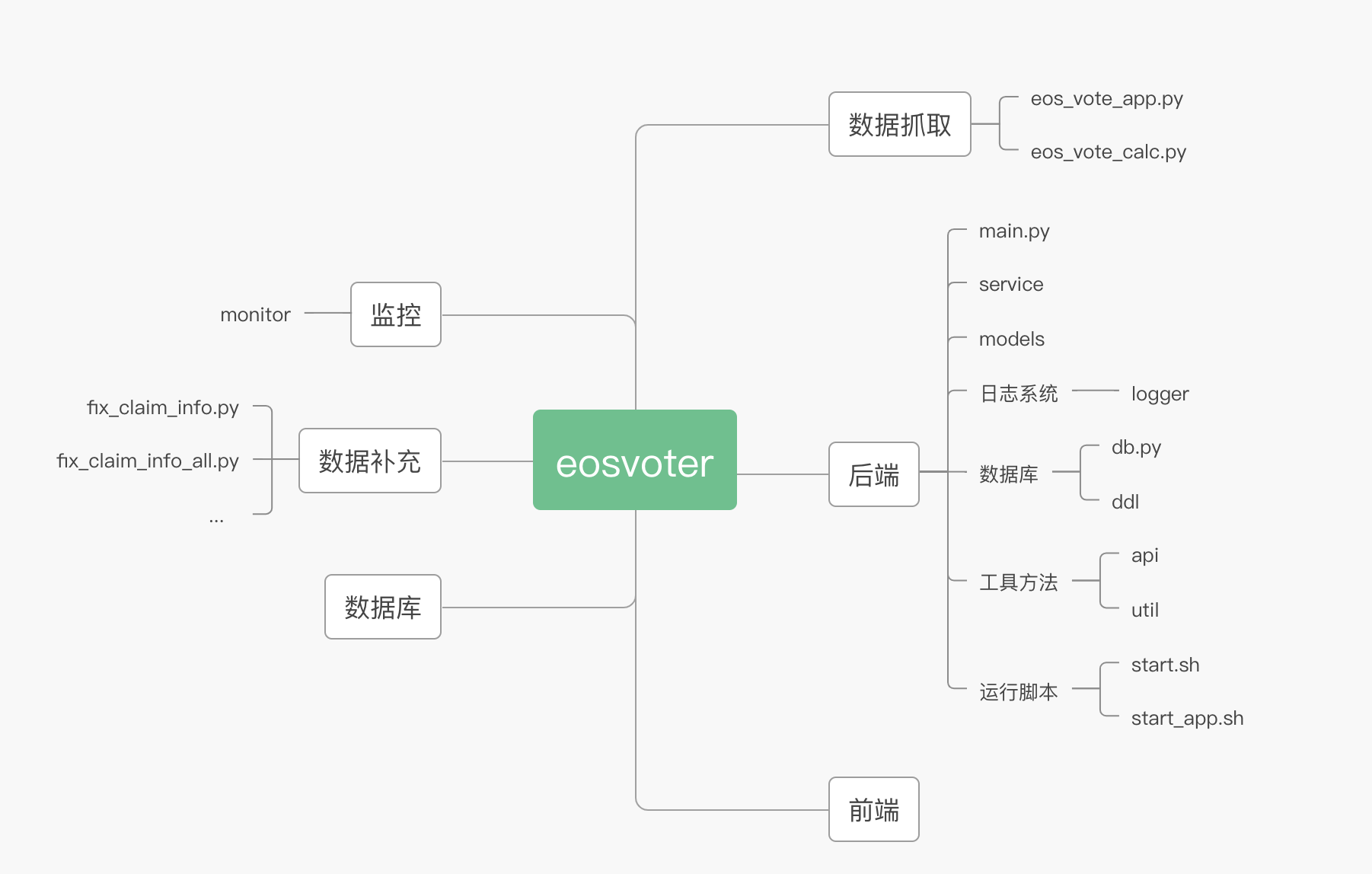
相关的项目如下:
相关的思维导图如下:
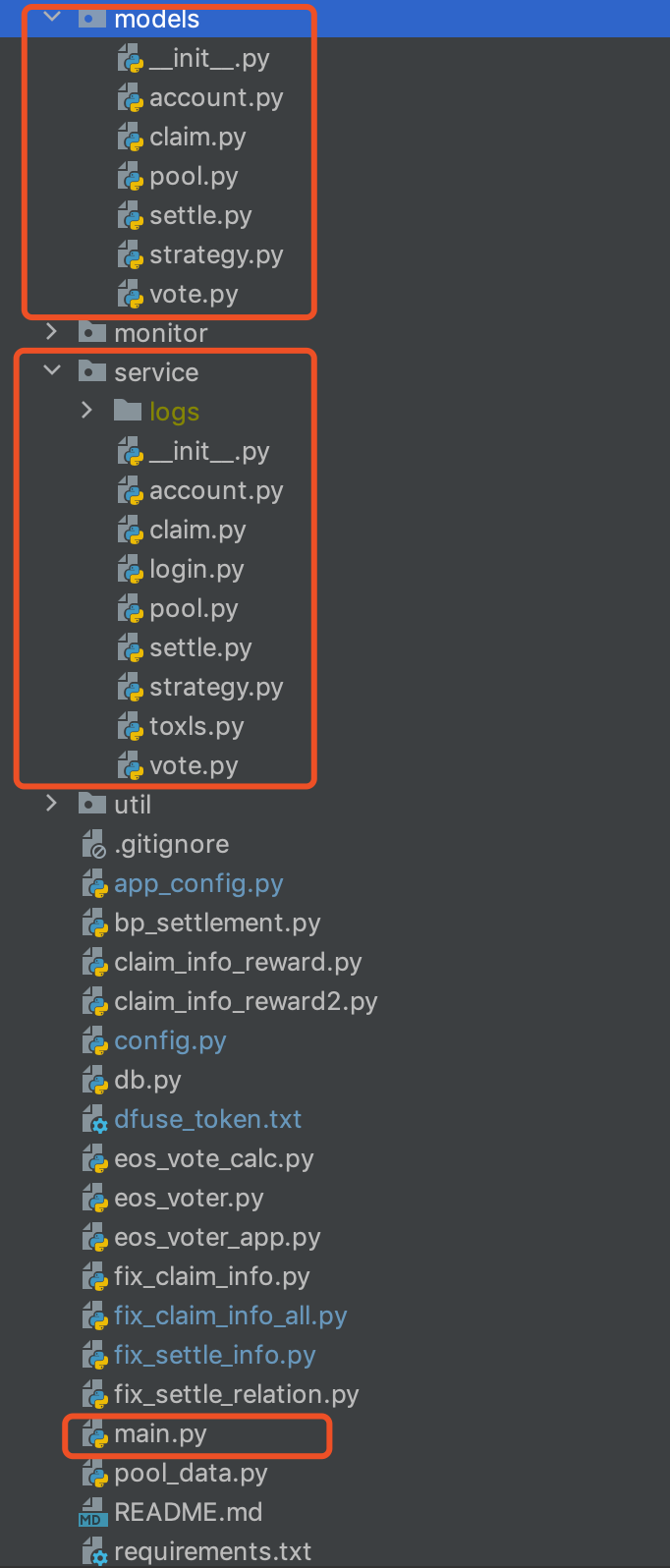
技术介绍
- python 3.7
- flask
项目介绍
在
中,我们知道,这个项目是 MVC 的设计思想,由于是前后端分离,所以,后端项目只有 MV。
关于 MVC 你可以参考我下面的博文:
这里先介绍一下支撑起项目架构的三个模块
- main.py
- models
- service
这里的 model 指的 项目中 models 文件夹,controll 指的是 service 文件夹。
main.py
这个是项目的主要入口,也是 flask 的启动文件,这里面主要用于请求的转发,不涉及一点业务逻辑代码,作用仅为转发请求。
贴一个代码看
1 |
|
对外暴漏 restful 接口,收到请求后,转发到对应的 service,而不会涉及逻辑代码。
这么做的目的是让代码更加精炼、有序。
service
这个文件夹中,对应的是 controll 层,又或者说服务层。里面的文件是
- claim.py
- pool.py
- …
这些一个个文件,对应的是以相同属性的数据表做的服务。
比如
- claim.py 对应
- t_claim_info 表
- pool.py 对应
- t_pool_data 表
- t_pool_info 表
这一层的逻辑是,接受从 main.py 发来的指令,然后调用相关的逻辑代码,通过 models 来对数据库进行增删改查,整个项目的所有逻辑和业务代码都在这个层中。
我以 pool.py 为例
文件会创建一个类,然后类中写各种逻辑代码
1 | from models.pool import Pool as pool_model |
从上面的代码可以知道,这里面是处理相关的逻辑和业务代码的。
models
这个文件夹相当于 model 层,负责对数据库的增删改查,没有相关的逻辑代码。
里面的文件和 service 的文件形式是一样的,都是以某一类同质的数据表来做为一个整体。
- account.py
- claim.py
- …
以 pool.py 为例
1 | import db |
可以看出,这个只负责对数据库进行增删改查。
其他
- 工具方法
- 日志系统
- 数据库
工具方法
api文件夹util文件夹
api 文件夹
里面的文件是
- eos_api.py
这里面主要是调用外部接口,举一个简单的例子
1 | def get_actions_hyperion(account, limit=30): |
util 文件夹
里面的文件是
- init.py
- auth.py
- times.py
- …
这里有各种工具方法,比如转化时间、转化数字等。
日志系统
是 logger 文件夹。
里面的文件是
- log.py
数据库
这个包含两个文件夹
- db.py 项目根目录下
- 封装了对数据库的操作,这个可以在上面的
models中可以看出
- 封装了对数据库的操作,这个可以在上面的
- ddl 文件夹
- 里面有
schema.sql库和表的初始化
- 里面有