如题。
参考资料
TensorFlow中的onehot有什么作用,为什么要使用onehot向量
对one hot 编码的理解,sklearn. preprocessing.OneHotEncoder 如何进行fit 的?
什么是one hot编码
数据科学家Rakshith Vasudev简要解释了one hot编码这一机器学习中极为常见的技术。
你可能在有关机器学习的很多文档、文章、论文中接触到“one hot编码”这一术语。本文将科普这一概念,介绍one hot编码到底是什么。
一句话概括:one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
通过例子可能更容易理解这个概念。
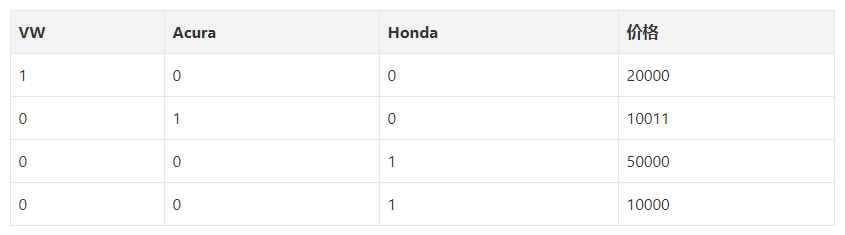
假设我们有一个迷你数据集:

其中,类别值是分配给数据集中条目的数值编号。比如,如果我们在数据集中新加入一个公司,那么我们会给这家公司一个新类别值4。当独特的条目增加时,类别值将成比例增加。
在上面的表格中,类别值从1开始,更符合日常生活中的习惯。实际项目中,类别值从0开始(因为大多数计算机系统计数),所以,如果有N个类别,类别值为0至N-1.
sklear的LabelEncoder可以帮我们完成这一类别值分配工作。
现在让我们继续讨论one hot编码,将以上数据集one hot编码后,我们得到的表示如下:
为什么要使用one hot编码
在我们继续之前,你可以想一下为什么不直接提供标签编码给模型训练就够了?为什么需要one hot编码?
标签编码的问题是它假定类别值越高,该类别更好。“等等,什么!”
让我解释一下:根据标签编码的类别值,我们的迷你数据集中VW > Acura > Honda。比方说,假设模型内部计算平均值(神经网络中有大量加权平均运算),那么1 + 3 = 4,4 / 2 = 2. 这意味着:VW和Honda平均一下是Acura。毫无疑问,这是一个糟糕的方案。该模型的预测会有大量误差。
我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征,原因正在于此。
当然,如果我们在设计网络的时候考虑到这点,对标签编码的类别值进行特别处理,那就没问题。不过,在大多数情况下,使用one hot编码是一个更简单直接的方案。
另外,如果原本的标签编码是有序的,那one hot编码就不合适了——会丢失顺序信息。
最后,我们用一个例子总结下本文:
假设“花”的特征可能的取值为daffodil(水仙)、lily(百合)、rose(玫瑰)。one hot编码将其转换为三个特征:is_daffodil、is_lily、is_rose,这些特征都是二进制的。
对one hot 编码的理解,sklearn. preprocessing.OneHotEncoder()如何进行fit()的?
网上关于One-hot编码的例子都来自于同一个例子,而且结果来的太抖了。查了半天,终于给搞清楚这个独热编码是怎么回事了,其实挺简单的,这里再做个总结。 首先,引出例子:
已知三个feature,三个feature分别取值如下: feature1=[“male”, “female”] feature2=[“from Europe”, “from US”, “from Asia”] feature3=[“uses Firefox”, “uses Chrome”, “uses Safari”, “uses Internet Explorer”]
如果做普通数据处理,那么我们就按0,1,2,3进行编号就行了。例如feature1=[0,1],feature2=[0,1,2],feature3=[0,1,2,3]。 那么,如果某个样本为[“male”,“from Asia”, “uses Chrome”],它就可以表示为[0,2,1]。 以上为普通编码方式。 独热编码(One-hot)换了一种方式编码,先看看百科定义的:
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。 例如对六个状态进行编码: 自然顺序码为 000,001,010,011,100,101 独热编码则是 000001,000010,000100,001000,010000,100000
通过以上可以看到,独热编码每一个码的总的位数取决于状态的种类数,每一个码里的“1”的位置,就代表了哪个状态生效。 还是回到我们最开始的例子,那么我们将它换成独热编码后,应该是: feature1=[01,10] feature2=[001,010,100] feature3=[0001,0010,0100,1000]
注意,独热编码还有个特性是,当某个特征里的某一状态生效后,此特征的其他状态因为是互斥的关系,必须全部为0,切必须全部添加到特征里,不能省略不写。 所以,对于前边样本[“male”,“from Asia”, “uses Chrome”],经过独热编码后,它应该为: [01,00, 000,000,100, 0000,0010,0000,0000] 。
以上的独热编码可以写成简写形式: [1,0, 0,0,1, 0,1,0,0]
最后,摘抄下独热编码的好处:
由于分类器往往默认数据数据是连续的,并且是有序的,但是在很多机器学习任务中,存在很多离散(分类)特征,因而将特征值转化成数字时,往往也是不连续的, One-Hot 编码解决了这个问题。 并且,经过独热编码后,特征变成了稀疏的了。这有两个好处,一是解决了分类器不好处理属性数据的问题,二是在一定程度上也起到了扩充特征的作用。
然后网上很多人举了一个sklearn. preprocessing.OneHotEncoder()的例子:例子如下:
1 | from sklearn.preprocessing import OneHotEncoder |
看了很多人的博客,都没懂,于是自己琢磨,原来是fit是看可以取多少个值。比如在
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
下面是颜色标注。

这个fit中,所有的数组第一个元素取值分别为:0,1,0,1(黄色标注的),最大为1,且为两种元素(0,1),说明用2个状态位来表示就可以了,且该维度的value值为2(该值只与最大值有关系,最大值为1)
所有的数组第二个元素取值分别为:0,1,2,0(红色标注的),最大为2,且为两种元素(0,1,2),说明用3个状态位来表示就可以了,且该维度的value值为3(该值只与最大值有关系,最大值为2)
所有的数组第三个元素取值分别为:3,0,1,2(天蓝色标注的),最大为3,且为两种元素(0,1,2,3),说明用4个状态位来表示就可以了,且该维度的value值为4(该值只与最大值有关系,最大值为4)
所以整个的value值为(2,3,4),这也就解释了 enc.n_values_等于array([2,3,4])的原因。而enc.feature_indices_则是特征索引,该例子中value值为(2,3,4),则特征索引从0开始,到2的位置为第一个,到2+3=5的位置为第二个,到2+3+4的位置为第三个,索引为array([0,2,5,9])
那么接下来理解
>>> enc.transform([[0, 1, 1]]).toarray()
array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.]])颜色标注

这个就好办了,enc.transform就是将[0,1,1]这组特征转换成one hot编码,toarray()则是转成数组形式。[0,1,1],
第一个元素是0,由于之前的fit的第一个维度为2(有两种表示:10,01.程序中10表示0,01表示1),所以用1,0表示用黄色标注);
第二个元素是1,由于之前的fit的第二个维度为3(有三种表示:100,010,001.程序中100表示0,010表示1,001表示2),所以用0,1,0表示用红色标注);
第三个元素是1,由于之前的fit的第三个维度为4(有四种表示:1000,0100,0010,0001.程序中1000表示0,0100表示1,0010表示2,0001表示3),
所以用0,1,0,0(用天蓝色标注)表示。综上所述:[0,1,1]就被表示为array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.]])。
全部截图如下:

优缺点
优点
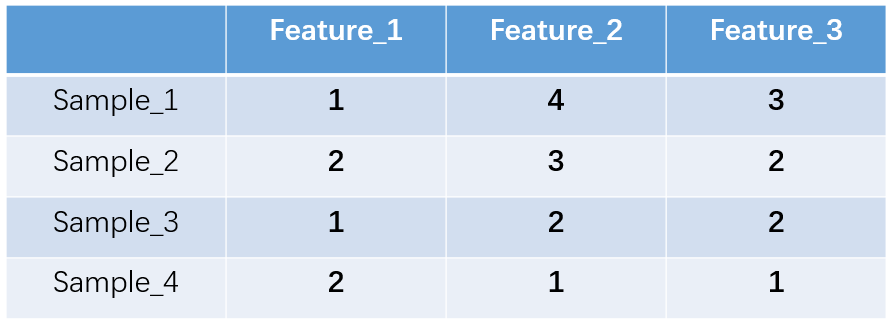

one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点
one-hot在提取文本特征上的应用
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
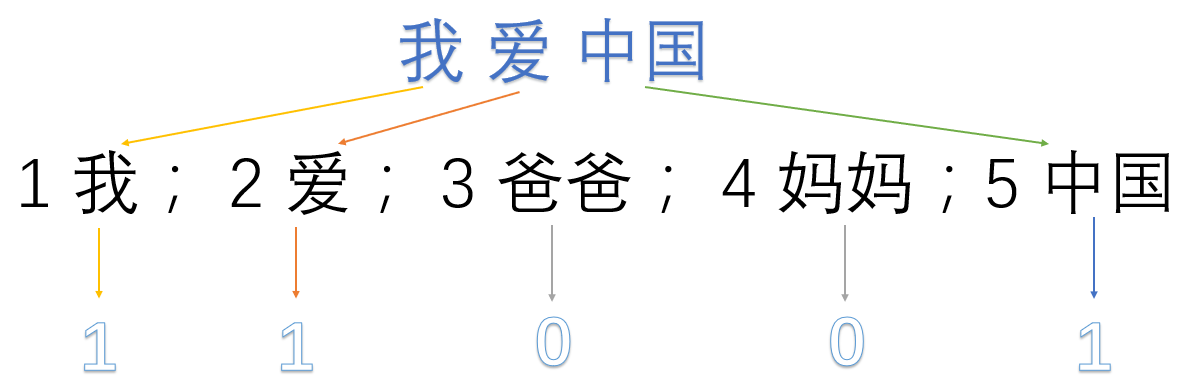
爸爸妈妈爱中国我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国然后使用one hot对每段话提取特征向量:
因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
1 | from sklearn import preprocessing |
TF-IDF
IF-IDF是信息检索(IR)中最常用的一种文本表示法。算法的思想也很简单,就是统计每个词出现的词频(TF),然后再为其附上一个权值参数(IDF)。举个例子:
现在假设我们要统计一篇文档中的前10个关键词,应该怎么下手?首先想到的是统计一下文档中每个词出现的频率(TF),词频越高,这个词就越重要。但是统计完你可能会发现你得到的关键词基本都是“的”、“是”、“为”这样没有实际意义的词(停用词),这个问题怎么解决呢?你可能会想到为每个词都加一个权重,像这种”停用词“就加一个很小的权重(甚至是置为0),这个权重就是IDF。下面再来看看公式:
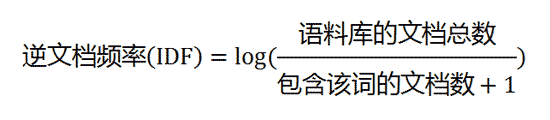
IF应该很容易理解就是计算词频,IDF衡量词的常见程度。为了计算IDF我们需要事先准备一个语料库用来模拟语言的使用环境,如果一个词越是常见,那么式子中分母就越大,逆文档频率就越小越接近于0。这里的分母+1是为了避免分母为0的情况出现。TF-IDF的计算公式如下:

根据公式很容易看出,TF-IDF的值与该词在文章中出现的频率成正比,与该词在整个语料库中出现的频率成反比,因此可以很好的实现提取文章中关键词的目的。
优缺点分析
优点:简单快速,结果比较符合实际
缺点:单纯考虑词频,忽略了词与词的位置信息以及词与词之间的相互关系。
sklearn实现tfidf
1 | from sklearn.feature_extraction.text import CountVectorizer |