如题。
python
序列(consequence)是 python 中一种数据结构,这种数据结构根据索引来获取序列中的对象。
python 中含有六种内建序列类:list, tuple, string, unicode, buffer, xrange。其中 xrange 比较特殊,它是一个生成器,其他几个类型具有的一些序列特性对它并不适合。
一般说来,具有序列结构的数据类型都可以使用:index, len, max, min, in, +, *, 切片。
切片操作不是列表特有的,python 中的有序序列都支持切片,如字符串,元组。
切片的返回结果类型和切片对象类型一致,返回的是切片对象的子序列,如:对一个列表切片返回一个列表,
字符串切片返回字符串。
切片生成的子序列元素是源版的拷贝。因此切片是一种浅拷贝。
格式:li[start : end : step]
start 是切片起点索引,end 是切片终点索引,但切片结果不包括终点索引的值。step 是步长默认是 1。
[start : end : step) 左开右闭1 | li=["A","B","C","D"] |
t=li[0:2] t=li[0:-2] t=li[-4:-2] t=li[-4:2]上面的结果都是一样的:t 为 [“A”,”B”]。
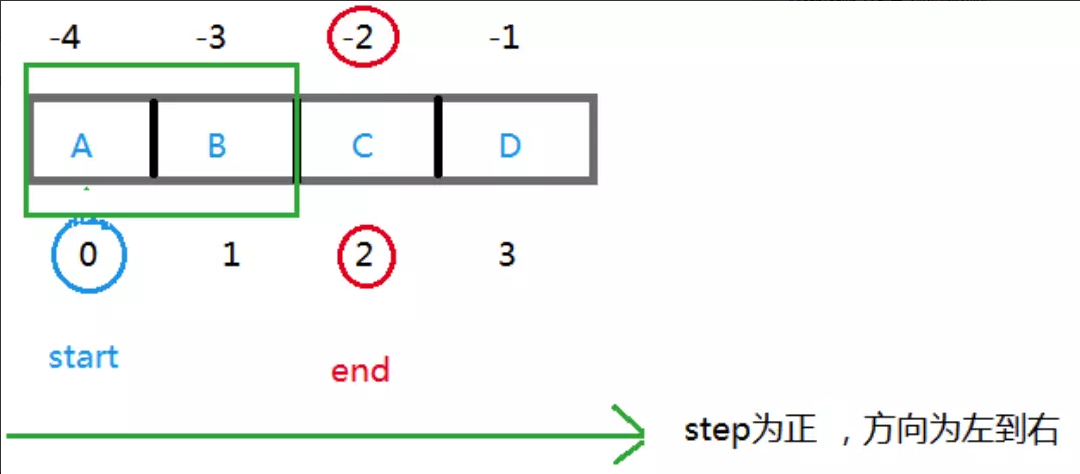
t=li[-1:-3:-1] t=li[-1:1:-1] t=li[3:1:-1] t=li[3:-3:-1]上面的结果都是一样的:t 为 [“D”,”C”]。

t=li[-1:-3] t=li[-1:1] t=li[3:1] t=li[3:-3]都切出空列表。

同时,step 的正负决定了切片结果的元素采集的先后。
省略 start 和 end 表示以原列表全部为目标。
t=li[::-1] t—>[“C”,”B”,”A”] #反向切,切出全部。
t=li[:] t—>[“A”,”B”,”C”,”D”] #正向切全部。
切片原理
需要注意的是,列表切片产生的是列表的副本,与原列表不是同一份空间。
x=[1,2,3]
y=x[:]
x[0]=-1
print(y) #输出[1,2,3]切片写操作
在2后面插入若干个元素,应该用列表
x=[1,2,3,4,5]
x[2:0]=100 #在2后面插入若干个元素,应该用列表
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: can only assign an iterable
x[2:0]=[100]
# [1, 2, 100, 3, 4, 5]删除切片
x = [1, 2, 100, 3, 4, 5]
del x[2:3] #删除切片
# [1, 2, 3, 4, 5]对于切片x[from:to],会进行预处理to=max(from+1,to)
x=[1,2,3,4,5]
x[2:1]=[100] #对于切片x[from:to],会进行预处理to=max(from+1,to)
# [1, 2, 100, 3, 4, 5]对于切片del操作,如果from>to,不执行任何操作
x = [1, 2, 100, 3, 4, 5]
del x[2:0]
# [1, 2, 100, 3, 4, 5]
del x[2:1]
# [1, 2, 100, 3, 4, 5]
del x[2:3]
# [1, 2, 3, 4, 5]切片原理解析
通过指定下标的方式来获得某一个数据元素,或者通过指定下标范围来获得一组序列的元素,这种访问序列的方式叫做切片。有些地方也把它称之为分片。
先从底层分析切片运算:
list 的切片,内部是调用 getitem,setitem,delitem 和 slice 函数。而 slice 函数又是和 range() 函数相关的。
给切片传递的键是一个特殊的 slice 对象。该对象拥有可描述所请求切片方位的属性。
a = [1,2,3,4,5,6]
x = a [ 1 : 5 ] # x = a.__getitem__(slice( 1, 5, None))
a [ 1 : 3 ] = [10, 11, 12 ] # a.__setitem__(slice(1, 3, None), [ 10, 11, 12 ])
del a [ 1 : 4 ] # a.__delitem__(slice(1, 4, None))看看代码具体实现
1 | def between(beg, end, mid): |
numpy
一维数组
一维数组很简单,基本和列表一致。
它们的区别在于数组切片是原始数组视图(这就意味着,如果做任何修改,原始都会跟着更改)。
这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copy())。
1 | import numpy as np #导入numpy |
二维数组
二维数组中,各索引位置上的元素不再是标量,而是一维数组.
arr1 = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
# array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
arr1[0]
# array([1, 2, 3])
arr1[1,2]
# 6想到了什么?咱们当做一个平面直角坐标系。
相当于arr1[x,y], x相当于行数,y相当于列数(必须声明,图中x和y标反了,但不影响理解)。
多维数组
先说明下reshape()更改形状:
np.reshape(a, newshape, order=’C’)
a :array_like以一个数组为参数。
newshape : int or tuple of ints。整数或者元组
顺便说明下,np.reshape()不更改原数组形状(会生成一个副本)。
arr1 = np.arange(12)
arr2 = arr1.reshape(2,2,3) #将arr1变为2×2×3数组
arr2
# array([[[ 0, 1, 2],
# [ 3, 4, 5]],
# [[ 6, 7, 8],
# [ 9, 10, 11]]])其实多维数组就相当于:
row * col * 列中列
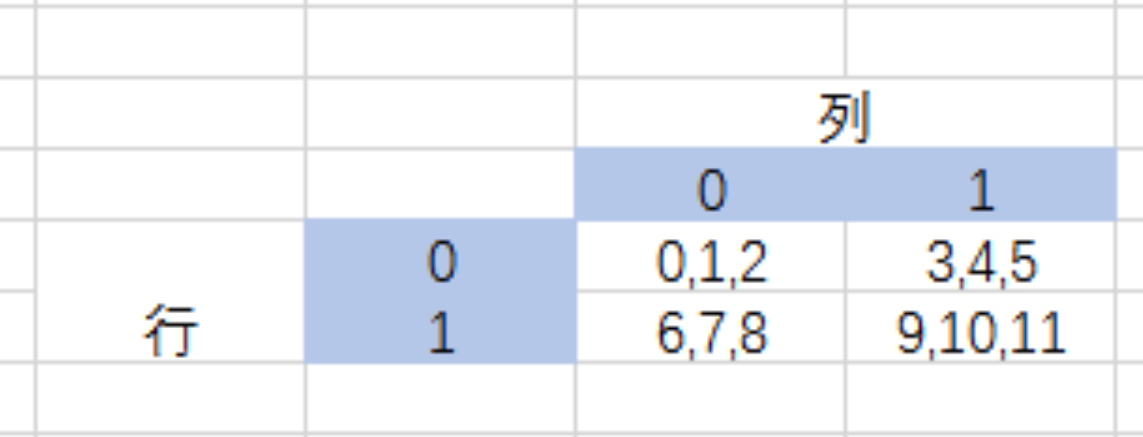
arr2[0] = 23 #赋值
arr2
#array([[[23, 23, 23],
# [23, 23, 23]],
# [[ 6, 7, 8],
# [ 9, 10, 11]]])切片索引
切片索引把每一行每一列当做一个列表就可以很容易的理解。
返回的都是数组。
再复杂一点:
我们想要获得下面这个数组第一行的第2,3个数值。
arr1 = np.arange(36)#创建一个一维数组。
arr2 = arr1.reshape(6,6) #更改数组形状。
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])为了得到第2,3个数,我们可以:
arr2[0,2:4]
Out[29]: array([2, 3])可以发现ndarray的切片其实与列表的切片是差不太多的。
arr2[1] #取得第2行
#v array([ 6, 7, 8, 9, 10, 11])
arr2[:,3] #取得第3列, 只有:代表选取整列(也就是整个轴)
# array([ 3, 9, 15, 21, 27, 33])
arr2[1:4,2:4] # 取得一个二维数组
# array([[ 8, 9],
# [14, 15],
# [20, 21]])
arr2[::2,::2] #设置步长为2
# array([[ 0, 2, 4],
# [12, 14, 16],
# [24, 26, 28]])
arr3 = arr2.reshape(4,3,3)
arr3[2:,:1] = 22 #对切片表达式赋值
# array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [22, 13, 14, 15, 16, 17],
# [22, 19, 20, 21, 22, 23],
# [22, 25, 26, 27, 28, 29],布尔型索引
arr3 = (np.arange(36)).reshape(6,6)#生成6*6的数组
# array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23],
# [24, 25, 26, 27, 28, 29],
# [30, 31, 32, 33, 34, 35]])
x = np.array([0, 1, 2, 1, 4, 5])
x == 1#通过比较运算得到一个布尔数组
# array([False, True, False, True, False, False], dtype=bool)
arr3[x == 1] #布尔索引
#[x == 1] 会返回一段索引
#array([[ 6, 7, 8, 9, 10, 11],
# [18, 19, 20, 21, 22, 23]])从结果上看,布尔索引取出了布尔值为True的行。
布尔型数组的长度和索引的数组的行数(轴长度)必须一致。
布尔型数组可与切片,整数(整数序列)一起使用。
arr3[x == 1,2:]#切片
# array([[ 8, 9, 10, 11],
# [20, 21, 22, 23]])
arr3[x == 1,-3:]#切片
# array([[ 9, 10, 11],
# [21, 22, 23]])
arr3[x == 1,3]#整数
# array([ 9, 21])!= 不等于符号。
~ 负号可以对条件进行否定。logical_not()函数也可以。
array3 = ([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
x = np.array([0, 1, 2, 1, 4, 5])
x != 1
Out[49]: array([ True, False, True, False, True, True], dtype=bool)
arr3[~(x == 1)] #实际类似于取反
Out[51]:
array([[ 0, 1, 2, 3, 4, 5],
[12, 13, 14, 15, 16, 17],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
arr3[np.logical_not(x == 1)] #作用于 ~ 相同
Out[53]:
array([[ 0, 1, 2, 3, 4, 5],
[12, 13, 14, 15, 16, 17],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])组合多个条件,使用布尔运算符&(和),|(或)
(x == 1 ) & (x == 4)#和
Out[67]: array([False, False, False, False, False, False], dtype=bool)
(x==1)|(x==4)#或
Out[68]: array([False, True, False, True, True, False], dtype=bool)
arr3[(x==1)|(x==4)]#布尔索引
Out[71]:
array([[ 6, 7, 8, 9, 10, 11],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]])通过以上的代码实验,我们也可以发现,布尔索引不更改原数组,创建的都是原数组的副本。
那这个东西能做什么呢?其他索引能做的,他基本也都可以。
比如有这样一个数组:
arr5 = np.random.randn(4,4)#randn返回一个服从标准正态分布的数组。
arr5
Out[77]:
array([[-0.64670829, 1.53428435, 0.20585387, 0.42680995],
[-0.63504514, 0.54542881, -0.82163028, -0.89835051],
[-0.66770299, 0.22617913, 0.16358189, -0.75074314],
[-0.25439447, -0.96135628, -0.10552532, -1.06962358]])我们要将arr5大于0的数值变为10:
arr5[arr5 > 0] = 10
arr5
Out[80]:
array([[ -0.64670829, 10. , 10. , 10. ],
[ -0.63504514, 10. , -0.82163028, -0.89835051],
[ -0.66770299, 10. , 10. , -0.75074314],当然,布尔索引也可以结合上面的运算符来进行操作。
花式索引
花式索引(Fancy indexing),指的是利用整数数组进行索引。
第一次看到这个解释,我是一脸懵的。
试验后,我才理解。
arr6 = np.empty((8,4))# 创建新数组,只分配内存空间,不填充值
for i in range(8):#给每一行赋值
arr6[i] = i
arr6
Out[5]:
array([[ 0., 0., 0., 0.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.],
[ 4., 4., 4., 4.],
[ 5., 5., 5., 5.],
[ 6., 6., 6., 6.],
[ 7., 7., 7., 7.]])
arr6[[2,6,1,7]] #花式索引
Out[14]:
array([[ 2., 2., 2., 2.],
[ 6., 6., 6., 6.],
[ 1., 1., 1., 1.],
[ 7., 7., 7., 7.]])我们可以看到花式索引的结果,以一个特定的顺序排列。
而这个顺序,就是我们所传入的整数列表或者ndarray。
这也为我们以特定的顺序来选取数组子集,提供了思路。
还可以使用负数(其实类似于列表)进行索引。
arr6[[-2,-6,-1]]
Out[21]:
array([[ 6., 6., 6., 6.],
[ 2., 2., 2., 2.],
[ 7., 7., 7., 7.]])一次传入多个索引数组,会返回一个一维数组,其中的元素对应各个索引元组。
arr7 = np.arange(35).reshape(5,7)#生成一个5*7的数组
arr7
Out[24]:
array([[ 0, 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12, 13],
[14, 15, 16, 17, 18, 19, 20],
[21, 22, 23, 24, 25, 26, 27],
[28, 29, 30, 31, 32, 33, 34]])
arr7[[1,3,2,4],[2,0,6,5]]
Out[27]: array([ 9, 21, 20, 33])经过对比可以发现,返回的一维数组中的元素,分别对应(1,2)、(3,0)….(这里用点来表示了,便于下面的解释,其实就是arr7[1,2])
这一样一下子就清晰了,我们传入来两个索引数组,相当于传入了一组平面坐标,从而进行了定位。
此处,照我这样理解的话,那么一个N维数组,我传入N个索引数组的话,是不是相当于我传入了一个N维坐标。
ar = np.arange(27).reshape(3,3,3)
ar
Out[31]:
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
ar[[1,2],[0,1],[2,2]]
Out[32]: array([11, 23])那么应该如何得到一个矩形区域呢。可以这样做:
arr7[[1,3,2,4]][:,[2,0,6,5]]
Out[33]:
array([[ 9, 7, 13, 12],
[23, 21, 27, 26],
[16, 14, 20, 19],
[30, 28, 34, 33]])那么上面这种得到矩形区域的方法,就相当于行与列去了交集。
此外还可用np.ix_函数,它的作用与上面的方法类似,只不过是将两个一维的数组转换为了一个可以选择矩形区域的索引器。
arr7[np.ix_([1,3,2,4],[2,0,6,5])]
Out[34]:
array([[ 9, 7, 13, 12],
[23, 21, 27, 26],
[16, 14, 20, 19],
[30, 28, 34, 33]])切片中的 None
None 相当于 numpy.newaxis, 增加了一个轴
1 | import numpy as np |