正则化缓解过拟合。
参考资料
TensorFlow从0到1 - 16 - L2正则化对抗“过拟合”
什么是过拟合
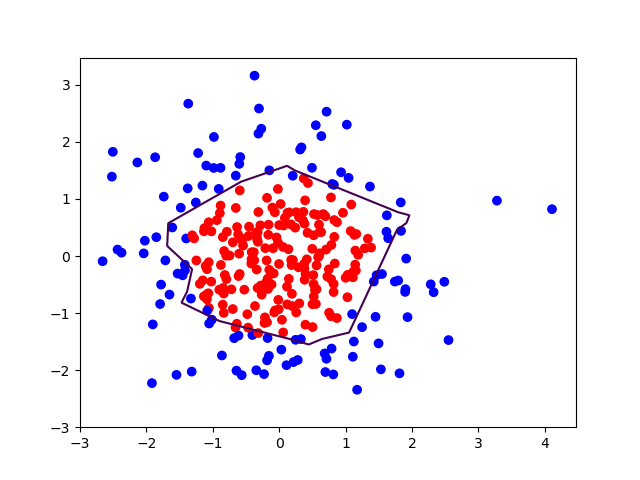
对于一些离散的二维空间中的样本点,下面两条曲线谁存在过拟合?

遵循奥卡姆剃刀的一派,主张“如无必要,勿增实体”。他们相信相对简单的模型泛化能力更好:上图中的蓝色直线,虽然只有很少的样本点直接落在它上面,但是不妨认为这些样本点或多或少包含一些噪声。基于这种认知,可以预测新样本也会在这条直线附近出现。
或许很多时候,倾向简单会占上风,但是真实世界的复杂性深不可测。虽然在自然科学中,奥卡姆剃刀被作为启发性技巧来使用,帮助科学家发展理论模型工具,但是它并没有被当做逻辑上不可辩驳的定理或者科学结论。总有简单模型表达不了,只能通过复杂模型来描述的事物存在。很有可能红色的曲线才是对客观世界的真实反映。
康德为了对抗奥卡姆剃刀产生的影响,创建了他自己的反剃刀:“存在的多样性不应被粗暴地忽视”。
阿尔伯特·爱因斯坦告诫:“科学理论应该尽可能简单,但不能过于简单。”
所以仅从上图来判断,一个理性的回答是:不知道。即使是如此简单的二维空间情况下,在没有更多的新样本数据做出验证之前,不能仅通过模型形式的简单或复杂来判定谁存在过拟合。
过拟合的判断
二维、三维的模型,本身可以很容易的绘制出来,当新的样本出现后,通过观察即可大致判断模型是否存在过拟合。
然而现实情况要复杂的多。对MNIST数字识别所采用的3层感知器——输入层784个神经元,隐藏层30个神经元,输出层10个神经元,包含23860个参数(23860 = 784 x 30 + 30 x 10 + 30 + 10),靠绘制模型来观察是不现实的。
最有效的方式是通过识别精度判断模型是否存在过拟合:比较模型对验证集和训练集的识别精度,如果验证集识别精度大幅低于训练集,则可以判断模型存在过拟合。
然而静态的比较已训练模型对两个集合的识别精度无法回答一个问题:过拟合是什么时候发生的?
要获得这个信息,就需要在模型训练过程中动态的监测每次迭代(Epoch)后训练集和验证集的识别精度,一旦出现训练集识别率继续上升而验证集识别率不再提高,就说明过拟合发生了。
这种方法还会带来一个额外的收获:确定作为超参数之一的迭代数(Epoch Number)的量级。更进一步,甚至可以不设置固定的迭代次数,以过拟合为信号,一旦发生就提前停止(early stopping)训练,避免后续无效的迭代。
过拟合检测
1个隐藏层,包含30个神经元;
学习率:3.0;
迭代数:30次;
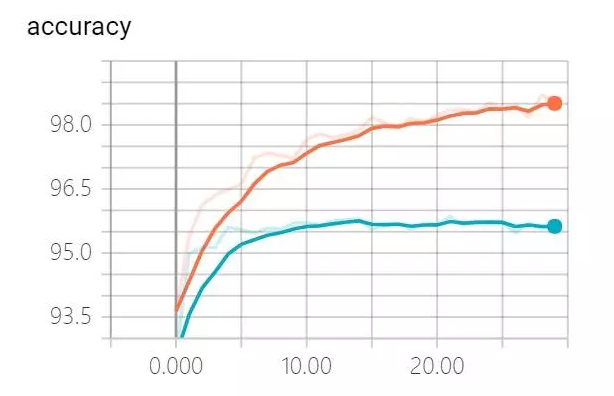
mini batch:10;训练过程中,分别对训练集和验证集的识别精度进行了跟踪,如下图所示,其中红线代表训练集识别率,蓝线代表测试集识别率。图中显示,大约在第15次迭代前后,测试集的识别精度稳定在95.5%不再提高,而训练集的识别精度仍然继续上升,直到30次迭代全部结束后达到了98.5%,两者相差3%。
由此可见,模型存在明显的过拟合的特征。
过拟合的对策:L2正则化
对抗过拟合最有效的方法就是增加训练数据的完备性,但它昂贵且有限。另一种思路是减小网络的规模,但它可能会因为限制了模型的表达潜力而导致识别精度整体下降。
本篇引入L2正则化(Regularization),可以在原有的训练数据,以及网络架构不缩减的情况下,有效避免过拟合。L2正则化即在损失函数C的表达式上追加L2正则化项:
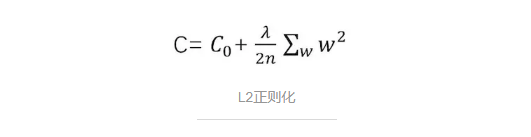
上式中的C0代表原损失函数,可以替换成均方误差、交叉熵等任何一种损失函数表达式。
关于L2正则化项的几点说明:
求和∑是对网络中的所有权重进行的;
λ(lambda)为自定义参数(超参数);
n是训练样本的数量(注意不是所有权重的数量!);
L2正则化并没有偏置参与;该如何理解正则化呢?
对于使网络达到最小损失的权重w,很可能有非常多不同分布的解:有的均值偏大、有的偏小,有的分布均匀,有的稀疏。那么在这个w的解空间里,该如何挑选相对更好的呢?正则化通过添加约束的方式,帮我们找到一个方向。
L2正则化表达式暗示着一种倾向:训练尽可能的小的权重,较大的权重需要保证能显著降低原有损失C0才能保留。
至于正则化为何能有效的缓解过拟合,这方面数学解释其实并不充分,更多是基于经验的认知。
L2正则化的实现
因为在原有损失函数中追加了L2正则化项,那么是不是得修改现有反向传播算法(BP1中有用到C的表达式)?答案是不需要。
C对w求偏导数,可以拆分成原有C0对w求偏导,以及L2正则项对w求偏导。前者继续利用原有的反向传播计算方法,而后者可以直接计算得到:
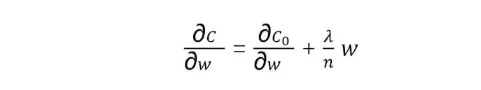
C对于偏置b求偏导保持不变:
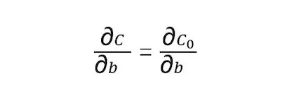
基于上述,就可以得到权重w和偏置b的更新方法:

TensorFlow实现L2正则化
TensorFlow的最优化方法tf.train.GradientDescentOptimizer包办了梯度下降、反向传播,所以基于TensorFlow实现L2正则化,并不能按照上节的算法直接干预权重的更新,而要使用TensorFlow方式:
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W_2)
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W_3)
regularizer = tf.contrib.layers.l2_regularizer(scale=5.0/50000)
reg_term = tf.contrib.layers.apply_regularization(regularizer)
loss = (tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(labels=y_, logits=z_3)) +
reg_term)对上述代码的一些说明:
将网络中所有层中的权重,依次通过tf.add_to_collectio加入到tf.GraphKeys.WEIGHTS中;
调用tf.contrib.layers.l2_regularizer生成L2正则化方法,注意所传参数scale=λ/n(n为训练样本的数量);
调用tf.contrib.layers.apply_regularization来生成损失函数的L2正则化项reg_term,所传第一个参数为上面生成的正则化方法,第二个参数为none时默认值为tf.GraphKeys.WEIGHTS;
最后将L2正则化reg_term项追加到损失函数表达式;向原有损失函数追加L2正则化项,模型和训练设置略作调整:
1个隐藏层,包含100个神经元;
学习率:0.5;
迭代数:30次;
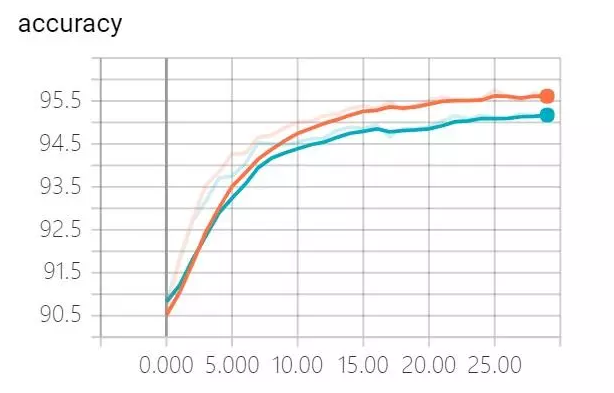
mini batch:10;重新运行训练,跟踪训练集和验证集的识别精度,如下图所示。图中显示,在整个30次迭代中,训练集和验证集的识别率均持续上升(都超过95%),最终两者的差距控制在0.5%,过拟合程度显著的减轻了。
需要注意的是,尽管正则化有效降低了验证集上过拟合程度,但是也降低了训练集的识别精度。所以在实现L2正则化时增加了隐藏层的神经元数量(从30到100)来抵消识别精度的下降。
以下为原 blog
正则化在损失函数中引入模型复杂度指标,利用给 W 加权值,弱化了训练数据的噪声。(一般不正则化 b)
loss = loss(y,y_) + REGULARIZER * loss(W)
REGULARIZER : 用超参数 REGULARIZER 给出参数 W 在总 loss 中的比例,及正则化的权重
W :需要正则化的参数在 tensorflow 中 loss(W) 的两种形式的代码
第一种
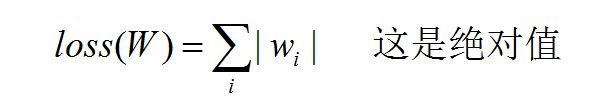
loss(W) = tf.contrib.layers.l1_regularizer(REGULARIZER)(w)第二种
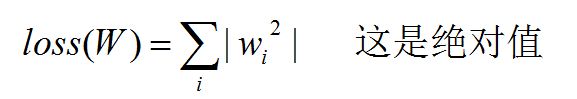
loss(W) = tf.contrib.layers.l2_regularizer(REGULARIZER)(w)后来的代码段
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
将内容加到集合对应位置做加法
即将 tf.contrib.layers.l2_regularizer(regularizer)(w) 加到 losses
loss = cem + tf.add_n(tf.get_collection('losses'))
其中 cem 代表交叉熵代码
1 | import tensorflow as tf |
数据展示
原始展示

无正则化

有正则化