1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
| 打开方式
open(s1,s2,s3)
s1:文件路径
s2:打开方式 默认方式为rt
s3:缓冲大小
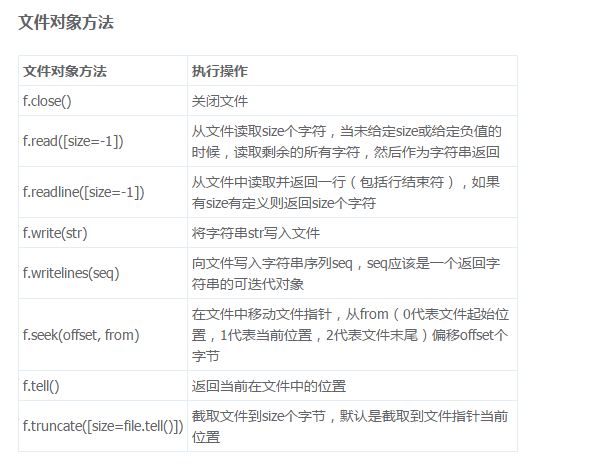
读取方式
read([size])
size:读取(size)个文件,默认为全部读完
怎么读是根据文件指针来的,由于初次open()文件,其指针在开头
调用read()方法,会全部读出,这时指针到了末尾
再次调用read()方法,文件内容虽然还有,但是已经读不出来了
想再读,可以重新打开
size是想要读取的字符数
read(5)
调用后,指针就会在5处
readline([size])
读取一行
readlines([size])
读取完文件,返回每一行所组成的列表
这个size不同于其他的size
在io.DEFAULT_BUFFER_SIZE中为8192
当size为2时,意味着一次性读取8192左右接近2倍数左右个字节当做一行(不能知道确切字节)
iter()
使用迭代器读取
文件写入方式
write(str):将字符串写入文件
writelines(list)
写多行到文件
文件打开方式
'r' 文件必须存在
'w' 文件不存在要创建,文件如果存在就先把文件内容清空再打开
'x' 如果文件存在,使用此模式打开会发生异常,这个方式创建文件并写入,是相对安全的
'a' 追加方式,在末尾写,文件不存在要创建
'b' 以二进制模式打开
't' 以文本模式打开(默认)
'+' 可读写模式
'r+'/'w+' 读写方式打开
以 r+ 方式打开:源文件内容为 123456
write("abc")
会变成 abc456
以w+方式打开:会将当前文件事先清空
'a+' 追加和读写方式打开
'rb','wb','ab','rb+','wb+','ab+' 二进制方式打开
文件在真正写的时候是在调用 close() 或者 flush() 方法后,在调用之前,数据是放在缓冲区的,当然当数据量很大时,会自动写入相应文件中
文件关闭
close()
文件指针(文件的写入和读取都是是根据指针位置来的)
seek(s1,[s2])
s1:偏移量,可以为负数
s2:偏移相对位置
os.SEEK_SET :相对文件起始位置 也可以写0
os.SEEK_CUR:相对文件当前位置
os.SEEK_END:相对文件结尾位置
f.seek(0,0) 指针定位到开头
tell() 告诉当前文件指针位置
file.fileno(): 文件描述符
file.mode: 文件打开权限
file.encoding: 文件编码格式
标准文件
标准输入:
sys.stdin
标准输出:
sys.stdout
标准错误:
sys.stderr
将unicode转化为utf-8可写入汉字
a = unicode.encode(u'慕课','utf-8')
创建一个utf-8或者其他格式的文件
利用 codecs 模块提供的方法指定编码格式文件
open(fname,mode,encoding,errors,buffering)
fname : 文件名称
mode : 打开方式
encoding : 编码格式
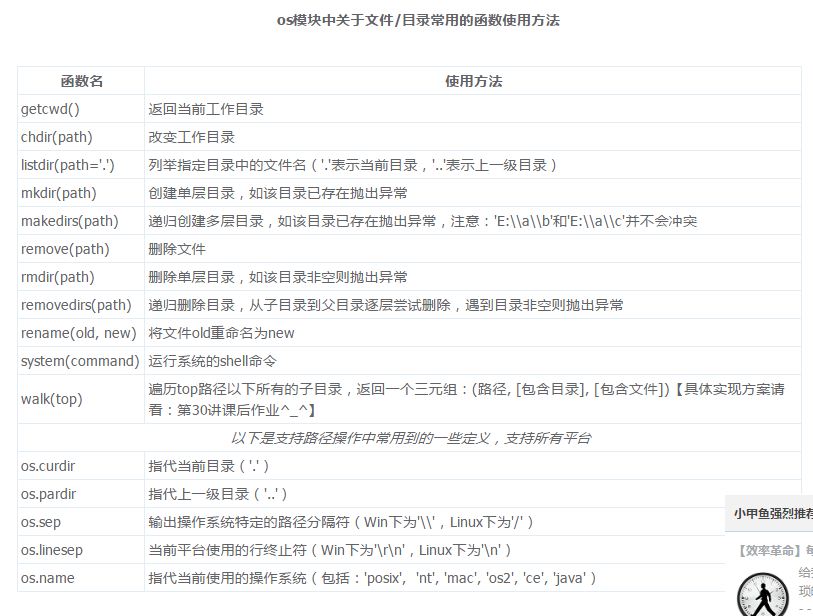
使用 os 模块(更加接近低层)
os.open(filename,flag,[mode])
flag:文件打开方式
os.O_CREAT 创建文件
os.O_RDONLY :只读方式打开
os.O_WRONLY :只写方式打开
os.O_RDWR : 读写方式打开
os.read(fd,buffersize)
os.write(fd,string)
os.lseek(fd,pos,how) :文件指针操作
os.close(fd)
os.access(path,mode) : 判断文件权限
mode:R_OK W_OK X_OK
os.listdir(path) : 返回当前目录下所有文件组成的文件列表
os.remove(path) : 删除文件
os.rename(old,new)
os.mkdir(path,[mode])
os.makedirs(path,[mode]) : 创建多级目录
os.removedirs(path) : 删除多级目录
os.path 模块使用
os.path.exists(path) : 当前路径是否存在
os.path.isdir(s) : 是否是一个目录
os.path.isfile(path) : 是否是一个文件
os.path.getsize(filename)
os.path.dirname(p) : 返回路径的目录
os.path.basename(p) : 返回路径的文件名
os.rmdir(path) : 删除目录(目录必须是空目录)
|