KNN算法是机器学习的一种很简单的分类算法。
原理
举一个二分类的例子。
电影有爱情片和动作片,如何区分两者是根据其内容得来的。所以,我们应该量化这些区别,并把有用的特征综合起来,当成特性向量。
如接吻次数和武打动作次数的比值;主人公的性别及数量等等。
我们量化了这些特性后,就可以作图,很容易的可以理解到相同类型的电影在图中的表现会产生聚类的效果。
这时,我们添加要测试的样本,根据特性找出样本点的位置,并且计算出该样本点和其他样本点的距离,记录下数据后,进行排序,我们可以取排序中最近距离的三个样本点,然后在这三个样本点中取最大概率的那个即是我们预测出来的电影类型。
如何计算测试样本和训练数据的距离
用的是勾股定理
设 A = (a1,b1) B = (a2,b2)
C = (a1 - a2,b1 - b2)
距离 d = [ (a1 - a2)^2 + (b1 - b2)^2 ] ^ 0.5
simple demo
首先我会创建四个数据,并给他们附上相应的标签值。
用 octave 画图:

贴上测试代码
1 | import numpy as np |
Halen的第1001个男人
下面我将举一个例子来说明,现实生活中 KNN 的运用,海伦在一个约会网站上经常约会别人,大概她约了1000余人,然后,她发现她约的人大概分为三种类型不喜欢,一般,很喜欢。于是,她搜集了这三种类型的人的相关数据。
分别是:每年飞行的里程数、玩游戏所消耗的时间百分比、每年消耗冰激凌的公升数。(相关数据你可以在我的github中找到,即 datingTestSet2.txt 文件中)
我用 octave 对特征一和特征二进行绘图。
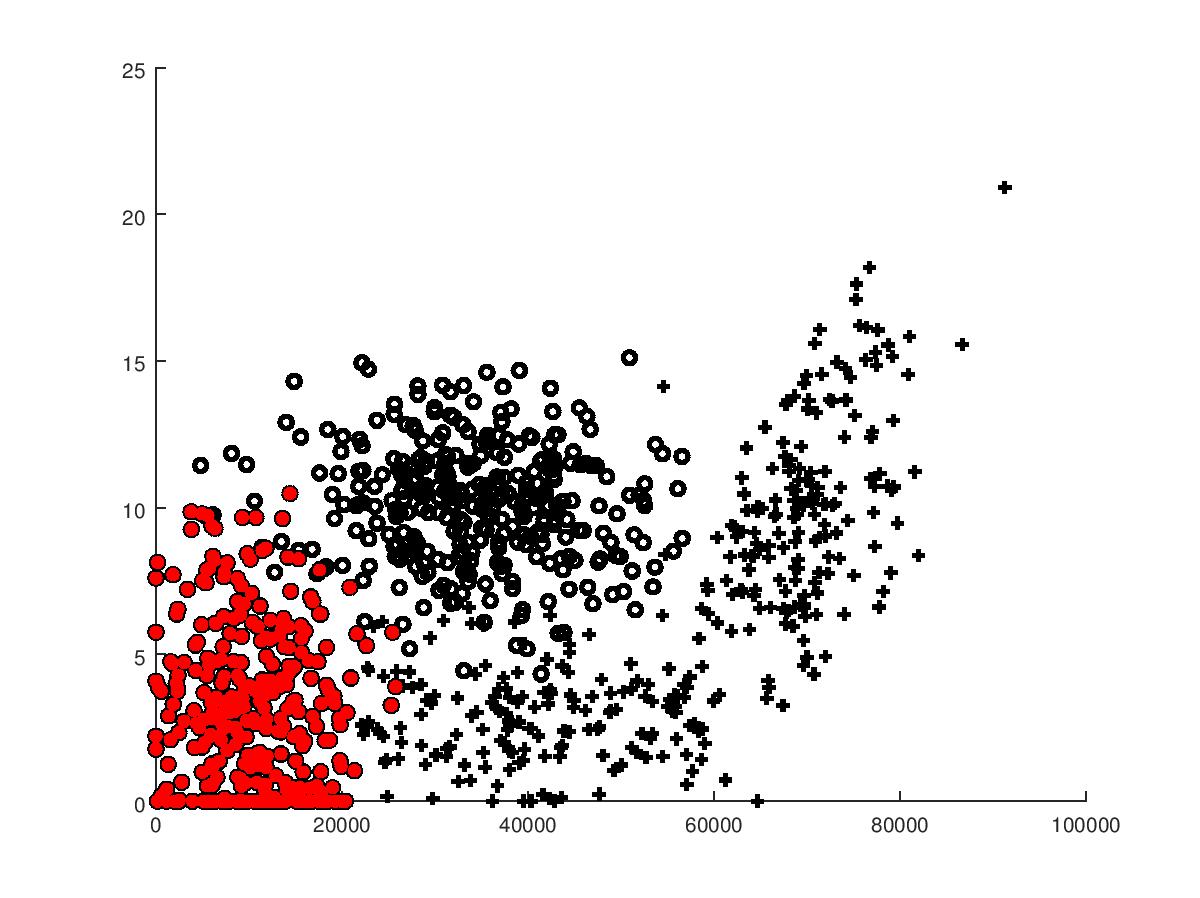
如图所示,三种魅力值不同的人几乎形成相应的集群。
数据归一化
按照上面,我们下一步的步骤是计算和集群之间的距离。但是,假设一个人的特征 里程数 20000 ,玩游戏比例 0.60 ,消耗冰激凌公升 1.1。
如果计算这一目标和某一样本的距离:
((20000 - 40000)^2 + (0.60 - 0)^2 + (1.1 - 1.0)^ 2) ^ 0.5
很明显因为里程数所占的权重最大,导致其他两个特征的数值无从紧要,所以,要进行归一化,使得各特征的权重一样。
归一化的原理就是将数据分布到 0 - 1 之间。
参见公式:
newValue = (oldValue - min) /(max - min)
其中,min 和 max 分别是数据集中的最小特征值和最大特征值。
代码,
参见我的 github
结果
error rate is : 0.050000
注意点
在 datingTestSet2.txt 中魅力值是用数字表示
在测试数据 datingTestSet.txt 中魅力值是用字符串表示
所以,在编写代码时注意区别
而 github 中的代码我是按照 datingTestSet.txt 编写的。
识别手写阿拉伯数字
我在 github KNN 的 digits 中放置了训练数据和测试数据。
如图所示(其中一个零):

图中是一个 32 * 32 的矩阵。
数据预处理
因为是 32 * 32,而在我们之前写的处理距离的函数中,不能用 32 * 32,而是将他们转换成一个 1024 * 1 的向量。相关代码,参见github
原理
其实看代码就已经很容易的明白原理了,但是为了节省时间,我在这里粗略的写一下原理。
因为,不同的阿拉伯数字会产生聚类的现象,所以,通过比较其中的 0 和 1 ,在计算距离,就可以得到相应的距离。然后排序。
原理写的很粗糙,因为我觉得很容易理解,而且天气太热了,我只想吃个雪糕而已。
就这样。