使用 pytorch 来实现 lstm。
相关博客
参考资料
参数含义
input_size:输入的维度,就是你输入x的向量大小(x向量里有多少个元素)hidden_size:h的维度,LSTM在运行时里面的维度。隐藏层状态的维数,即隐藏层节点的个数,这个和单层感知器的结构是类似的。num_layers:堆叠LSTM的层数,默认值为1,LSTM堆叠的层数,默认值是1层,如果设置为2,第二个LSTM接收第一个LSTM的计算结果。也就是第一层输入[X0 X1 X2 ... Xt],计算出[h0 h1 h2 ... ht],第二层将[h0 h1 h2 ... ht]作为[X0 X1 X2 ... Xt]输入再次计算,输出最后的[h0 h1 h2 ... ht]。bias:偏置 ,默认值:Truebatch_first: 如果是True,则input为(batch,seq,input_size)。默认值为:False(seq_len, batch, input_size),torch.LSTM中batch_size维度默认是放在第二维度,故此参数设置可以将batch_size放在第一维度。如:input默认是(4,1,5),中间的1是batch_size,指定batch_first=True后就是(1,4,5)。所以,如果你的输入数据是二维数据的话,就应该将batch_first设置为True。dropout:默认值0。是否在除最后一个RNN层外的其他RNN层后面加dropout层。输入值是0-1之间的小数,表示概率。0表示0概率dripout,即不dropoutbidirectional:是否双向传播,默认值为False
参数详解
hidden_size
这个参数是指 lstm 中的隐藏层的节点个数。
对于 DNN 又或者是 CNN 来讲,我们都是把整个变量一起输进去,然后得到输出,但是,对于 RNN 结构,我们有一个循环的概念。假如说,一张图片为 28 * 28 ,那么,我们会先输入一个 28 ,得到输出,并且,更新内部参数后,再输入一个 28 ,接着更新内部参数,得到输出。这样循环输入,直到最后全部输进去。
这里要注意的是,虽然输入是循环的,但是,这些输入共享的是一套参数「内部参数」。
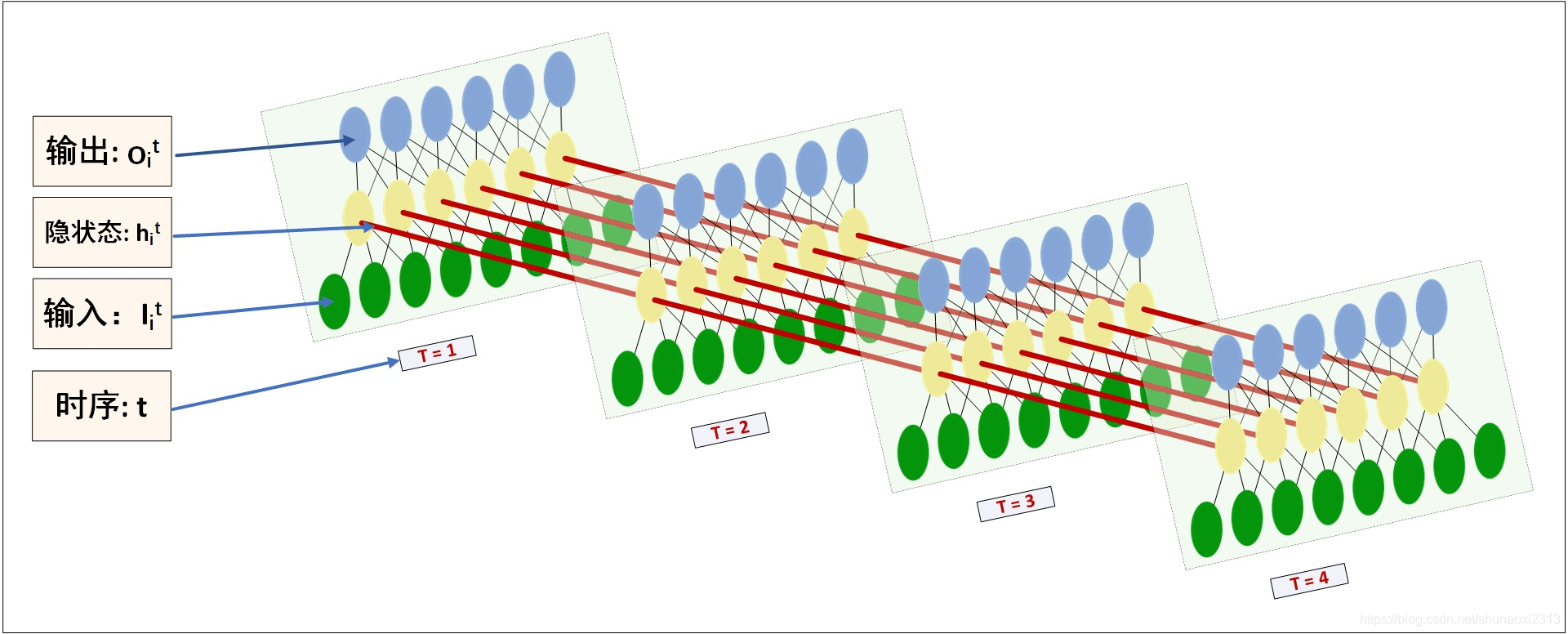
从上面这张图就可以清晰看出,整个训练过程。
- 绿色的代表的是输入
- 黄色的代表的是隐藏层
- 蓝色的代表的是输出,可以看出,蓝色的节点数目和黄色的节点数目是一样的
这里有一点需要注意的是,假设我们的数据被我们分成 10 * 20,则,我们只需要把 hidden_size 设置为 20 ,不用去管前面的 10,lstm 会根据数据,自己进行循环。
output
那,RNN 对应的输出到底是什么?
先看一张图

可以看出来,output 是每一次循环得到的输出集合。
我们的输入是 (20,10,30) 也就是一个数据的维度信息是 10 * 30 ,一共有 20 个这样的信息,即,batch_size = 20 ,timestep = 10 ,hidden_size = 30。
我们经历第一个 timestep 得到的输出是 (20,1,30),再经历完所有的循环后,得到的输出尺寸是 (20,10,30)。
但是,我们只需要最后那个时刻的输出就好了。
一个简单的小例子
1 | class RNN(nn.Module): |
输出为
1 | lstm out size: |
LSTM 实现 MNIST
直接使用 pytorch 定义好的 LSTM ,虽然简单,但是丧失了灵活性。
这个暂时还没运行过。。。网上的例子。
1 | import torch |