这个真的是值得人研究的事情,如果,gpu 利用率很低,那还不如 cpu 来的舒爽。
参考资料
我会结合我自己的经验加上这篇博文来做一个总结!
在深度学习模型训练过程中,在服务器端或者本地pc端,输入nvidia-smi来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util),然后采用top来查看CPU的线程数(PID数)和利用率(%CPU)。往往会发现很多问题,比如
- GPU内存占用率低
- 显卡利用率低
- CPU百分比低等等
GPU内存占用率问题
这往往是由于
模型的大小batch size的大小
来影响这个指标。
当你发下你的GPU占用率很小的时候,比如40%,70%,等等。
此时,如果你的网络结构已经固定,此时只需要改变batch size的大小,就可以尽量利用完整个GPU的内存。GPU的内存占用率主要是模型的大小,包括网络的宽度,深度,参数量,中间每一层的缓存,都会在内存中开辟空间来进行保存,所以模型本身会占用很大一部分内存。
其次是batch size的大小,也会占用影响内存占用率。batch size设置为128,与设置为256相比,内存占用率是接近于2倍关系。当你batch size设置为128,占用率为40%的话,设置为256时,此时模型的占用率约等于80%,偏差不大。所以在模型结构固定的情况下,尽量将batch size设置大,充分利用GPU的内存。(GPU会很快的算完你给进去的数据,主要瓶颈在CPU的数据吞吐量上面。)
GPU利用率问题
这个是Volatile GPU-Util表示,当没有设置好CPU的线程数时,这个参数是在反复的跳动的,0%,20%,70%,95%,0%。这样停息1-2 秒然后又重复起来。其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐起计算来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。因此,这个GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。最好当然就是换更好的四代或者更强大的内存条,配合更好的CPU。
另外的一个方法是,在PyTorch这个框架里面,数据加载Dataloader上做更改和优化,包括num_workers(线程数),pin_memory,会提升速度。解决好数据传输的带宽瓶颈和GPU的运算效率低的问题。在TensorFlow下面,也有这个加载数据的设置。
pytorch
1 | torch.utils.data.DataLoader(image_datasets[x], |
为了提高利用率,首先要将num_workers(线程数)设置得体,4,8,16是几个常选的几个参数。本人测试过,将num_workers设置的非常大,例如,24,32,等,其效率反而降低,因为模型需要将数据平均分配到几个子线程去进行预处理,分发等数据操作,设高了反而影响效率。
当然,线程数设置为1,是单个CPU来进行数据的预处理和传输给GPU,效率也会低。其次,当你的服务器或者电脑的内存较大,性能较好的时候,建议打开pin_memory打开,就省掉了将数据从CPU传入到缓存RAM里面,再给传输到GPU上;为True时是直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
tensorflow
1 | dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls) |
ps: tensorflow 的代码我没有试过
CPU的利用率问题
很多人在模型训练过程中,不只是关注GPU的各种性能参数,往往还需要查看CPU处理的怎么样,利用的好不好。这一点至关重要。
但是对于CPU,不能一味追求超高的占用率。如图所示,对于14339这个程序来说,其CPU占用率为2349%(我的服务器是32核的,所以最高为3200%)。这表明用了24核CPU来加载数据和做预处理和后处理等。其实主要的CPU花在加载传输数据上。此时,来测量数据加载的时间发现,即使CPU利用率如此之高,其实际数据加载时间是设置恰当的DataLoader的20倍以上,也就是说这种方法来加载数据慢20倍。
当DataLoader的num_workers=0时,或者不设置这个参数,会出现这个情况。

下面的数据可以看出,加载数据的实际是12.8s,模型GPU运算时间是0.16s,loss反传和更新时间是0.48s。此时,即使CPU为2349%,但模型的训练速度还是非常慢,而且,GPU大部分是时间是空闲等待状态。
当 num_workers = 0 时,模型每个阶段的时间统计
load data time: 12.8
model process time is: 0.159
loss backward and para update time : 0.47当我将num_workers=1时,出现的时间统计如下,load data time为6.3,数据加载效率提升1倍。且此时的CPU利用率为170%,用的CPU并不多,性能提升1倍。
当 num_workers = 1 时,模型每个阶段的时间统计
load data time: 6.33
model process time is: 0.1244
loss backward and para update time : 0.45此时,查看GPU的性能状态(我的模型是放在1,2,3号卡上训练),发现,虽然GPU(1,2,3)的内存利用率很高,基本上为98%,但是利用率为0%左右。表面此时网络在等待从CPU传输数据到GPU,此时CPU疯狂加载数据,而GPU处于空闲状态。
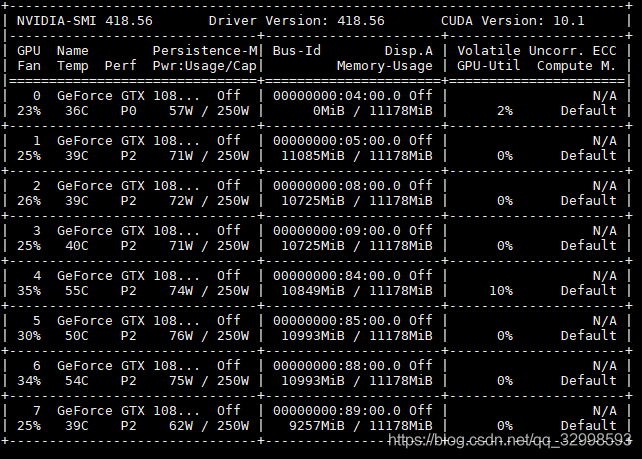
由此可见,CPU的利用率不一定最大才最好。
对于这个问题,解决办法是,增加DataLoader这个num_wokers的个数,主要是增加子线程的个数,来分担主线程的数据处理压力,多线程协同处理数据和传输数据,不用放在一个线程里负责所有的预处理和传输任务。
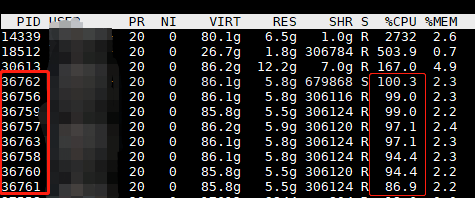
我将num_workers=8,16都能取得不错的效果。此时用top查看CPU和线程数,如果我设置为num_workers=8,线程数有了8个连续开辟的线程PID,且大家的占用率都在100%左右,这表明模型的CPU端,是较好的分配了任务,提升数据吞吐效率。效果如下图所示,CPU利用率很平均和高效,每个线程是发挥了最大的性能。
此时,在用nvidia-smi查看GPU的利用率,几块GPU都在满负荷,满GPU内存,满GPU利用率的处理模型,速度得到巨大提升。
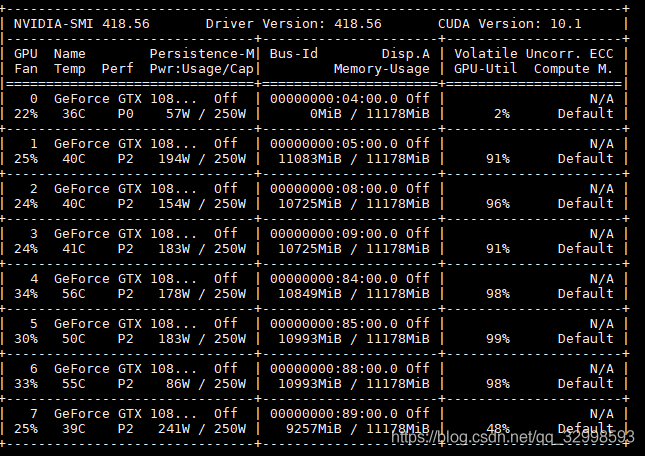
上图中可以看见,GPU的内存利用率最大化,此时是将batch size设置的较大,占满了GPU的内存,然后将num_workers=8,分配多个子线程,且设置pin_memory=True,直接映射数据到GPU的专用内存,减少数据传输时间。GPU和CPU的数据瓶颈得到解决。整体性能得到权衡。
总结
对上面的分析总结一下。
第一是增加batch size,增加GPU的内存占用率,尽量用完内存,而不要剩一半,空的内存给另外的程序用,两个任务的效率都会非常低。
第二,在数据加载时候,将num_workers线程数设置稍微大一点,推荐是8,16等,且开启pin_memory=True。不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下。
另外,我在跑我自己代码的时候,发现,耗费时间最多的地方时数据的预处理
数据预处理
1 | class TrainDataset(Dataset): |
在使用的过程中
1 | train_loader = DataLoader(dataset=trainDataset, batch_size=64, shuffle=True) |
每一次 for batch_idx, (data, target) in enumerate(train_loader) 都要重新来处理一边数据,比如归一化等,所以,很麻烦。
所以,我的做法是提前将数据处理好,将处理好的数据放在 csv等格式的文件中,然后直接读取文件就好了。我的代码提升了 50 倍。
相关命令
top- 查看
cpu - 实时查看你的
CPU的进程利用率,这个参数对应你的num_workers的设置
- 查看
watch -n 0.5 nvidia-smi- 每
0.5秒刷新并显示显卡设置 - 实时查看你的
GPU的使用情况,这是GPU的设置相关。这两个配合好。包括batch_size的设置。
- 每