这是深度学习图像处理中非常经典的网络结构,建议好好看。
参考资料
前言
VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
VGG原理
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49xC^2 ,这里 C 指的是输入和输出的通道数。很明显,27xC^2小于49xC^2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
这里解释一下为什么使用2个3x3卷积核可以来代替5*5卷积核:
5x5卷积看做一个小的全连接网络在5x5区域滑动,我们可以先用一个3x3的卷积滤波器卷积,然后再用一个全连接层连接这个3x3卷积输出,这个全连接层我们也可以看做一个3x3卷积层。这样我们就可以用两个3x3卷积级联(叠加)起来代替一个 5x5卷积。
具体如下图所示:
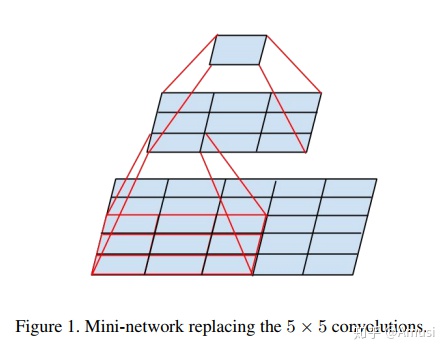
至于为什么使用3个3x3卷积核可以来代替7*7卷积核,推导过程与上述类似,大家可以自行绘图理解。
VGG网络结构
下面是VGG网络的结构(VGG16和VGG19都在):
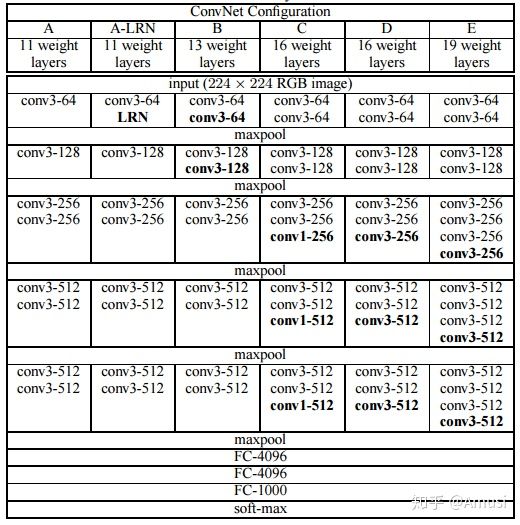
VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图中的D列所示
VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图中的E列所示
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
VGG优缺点
VGG优点
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸
(3x3)和最大池化尺寸(2x2)。 - 几个小滤波器
(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好: - 验证了通过不断加深网络结构可以提升性能。
VGG缺点
- VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,AlexNet只有200m,GoogLeNet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。