这个是 python 的参数传递的机理所在,值得一读。
参考资料
赋值、拷贝
在python中,类型属于对象,变量是没有类型的,这正是python的语言特性,也是吸引着很多pythoner的一点。所有的变量「整数、string、函数等」都可以理解是内存中一个对象的“引用”,或者,也可以看似c中void*的感觉。所以,希望大家在看到一个python变量的时候,把变量和真正的内存对象分开。
类型是属于对象的,而不是变量。
背书python中的引用对象问题:
python不允许程序员选择采用传值还是传引用。Python参数传递采用的肯定是“传对象引用”的方式。实际上,这种方式相当于传值和传引用的一种综合。如果函数收到的是一个可变对象(比如字典或者列表)的引用,就能修改对象的原始值——相当于通过“传引用”来传递对象。如果函数收到的是一个不可变对象(比如数字、字符或者元组)的引用,就不能直接修改原始对象——相当于通过“传值’来传递对象。
当人们复制列表或字典时,就复制了对象列表的引用同,如果改变引用的值,则修改了原始的参数。
为了简化内存管理,Python通过引用计数机制实现自动垃圾回收功能,Python中的每个对象都有一个引用计数,用来计数该对象在不同场所分别被引用了多少次。每当引用一次Python对象,相应的引用计数就增1,每当消毁一次Python对象,则相应的引用就减1,只有当引用计数为零时,才真正从内存中删除Python对象。
python的赋值
在 python 中赋值语句总是建立对象的引用值,而不是复制对象。因此,python 变量更像是指针,而不是数据存储区域。
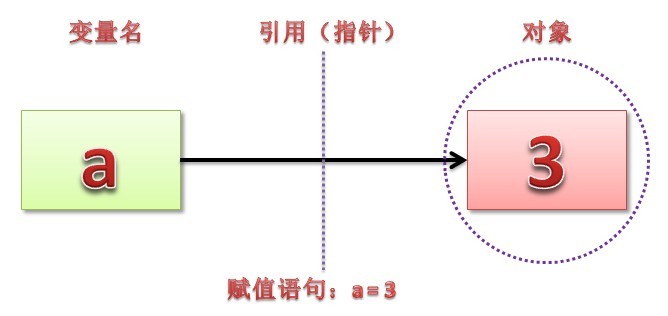
这点和大多数 OO 语言类似吧,比如 C++、java 等 ~
一个赋值问题
在Python中,令values=[0,1,2];values[1]=values,为何结果是[0,[...],2]?
>>> values = [0, 1, 2]
>>> values[1] = values
>>> values
[0, [...], 2] # 实际结果, 为何要赋值无限次?
[0, [0, 1, 2], 2] # 预想结果可以说 Python 没有赋值,只有引用。你这样相当于创建了一个引用自身的结构,所以导致了无限循环。为了理解这个问题,有个基本概念需要搞清楚。
Python 没有「变量」,我们平时所说的变量其实只是「标签」,是引用。
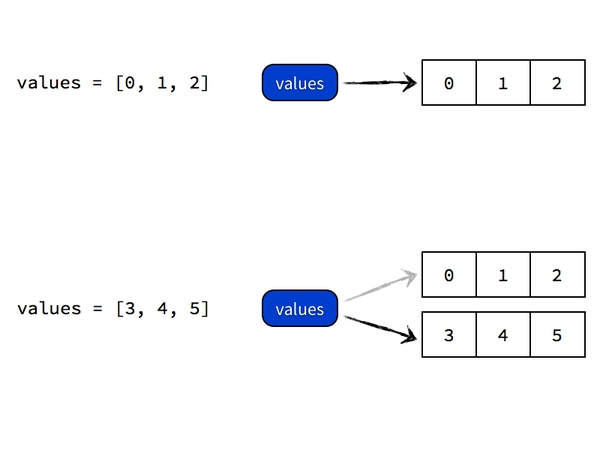
执行 values = [0, 1, 2] 的时候,Python 做的事情是首先创建一个列表对象 [0, 1, 2],然后给它贴上名为 values 的标签。
如果随后又执行 values = [3, 4, 5] 的话,Python 做的事情是创建另一个列表对象 [3, 4, 5],然后把刚才那张名为 values 的标签从前面的 [0, 1, 2] 对象上撕下来,重新贴到 [3, 4, 5] 这个对象上。
至始至终,并没有一个叫做 values 的列表对象容器存在,Python 也没有把任何对象的值复制进 values 去。过程如图所示:
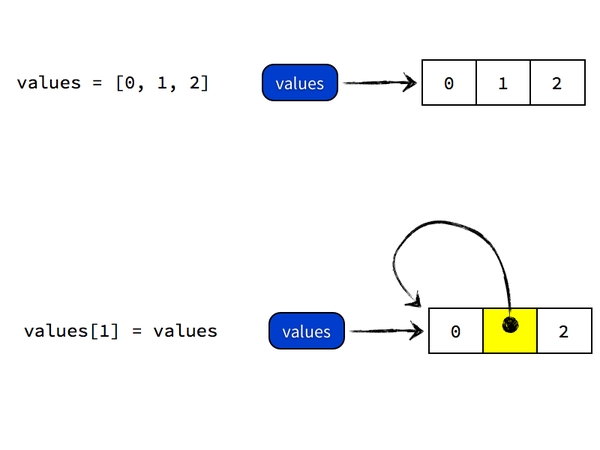
执行 values[1] = values 的时候,Python 做的事情则是把 values 这个标签所引用的列表对象的第二个元素指向 values 所引用的列表对象本身。执行完毕后,values 标签还是指向原来那个对象,只不过那个对象的结构发生了变化,从之前的列表 [0, 1, 2] 变成了 [0, ?, 2],而这个 ? 则是指向那个对象本身的一个引用。如图所示:
浅复制及其风险
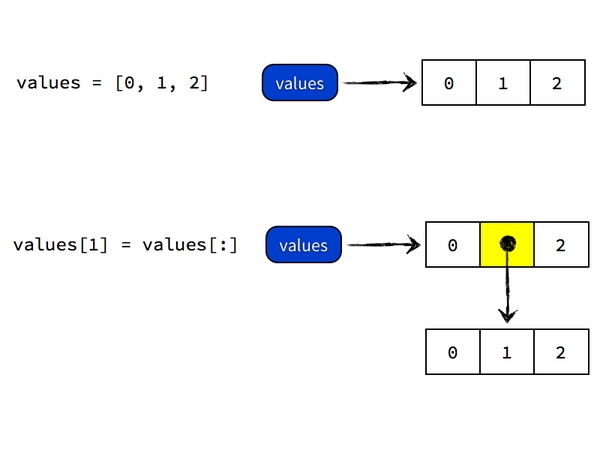
要达到你所需要的效果,即得到 [0, [0, 1, 2], 2] 这个对象,你不能直接将 values[1] 指向 values 引用的对象本身,而是需要吧 [0, 1, 2] 这个对象「复制」一遍,得到一个新对象,再将 values[1] 指向这个复制后的对象。Python 里面复制对象的操作因对象类型而异,复制列表 values 的操作是
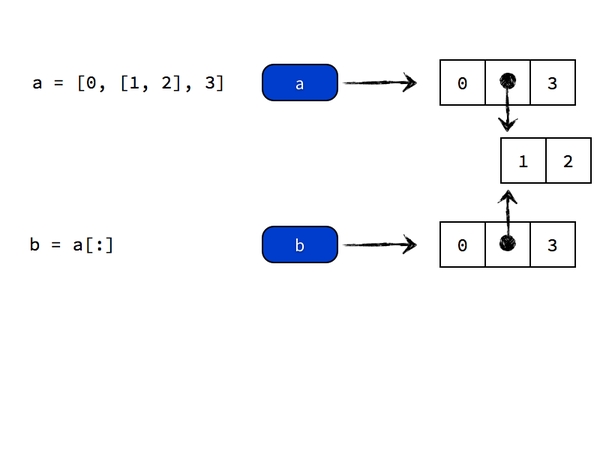
values[:] #生成对象的拷贝或者是复制序列,不再是引用和共享变量,但此法只能顶层复制所以你需要执行 values[1] = values[:]
Python 做的事情是,先 dereference 得到 values 所指向的对象 [0, 1, 2],然后执行 [0, 1, 2][:] 复制操作得到一个新的对象,内容也是 [0, 1, 2],然后将 values 所指向的列表对象的第二个元素指向这个复制二来的列表对象,最终 values 指向的对象是 [0, [0, 1, 2], 2]。过程如图所示:
往更深处说,values[:] 复制操作是所谓的「浅复制」(shallow copy),当列表对象有嵌套的时候也会产生出乎意料的错误,比如为何要赋值无限次
1 | a = [0, [1, 2], 3] |
问:此时 a 和 b 分别是多少?
正确答案是 a 为 [8, [1, 9], 3],b 为 [0, [1, 9], 3]。发现没?b 的第二个元素也被改变了。想想是为什么?不明白的话看下图
深复制
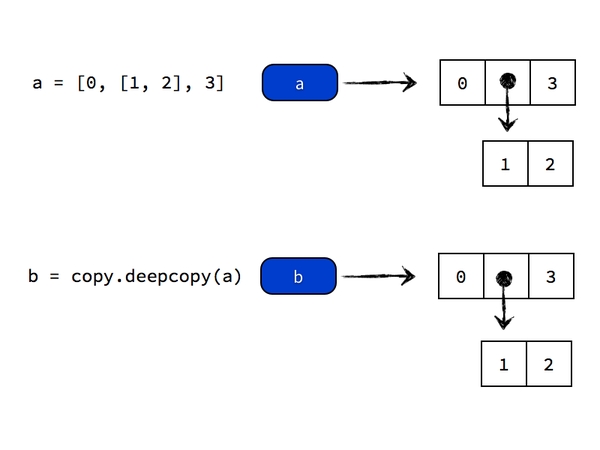
正确的复制嵌套元素的方法是进行「深复制」(deep copy),方法是
1 | import copy |
引用 VS 拷贝
- 没有限制条件的分片表达式(L[:])能够复制序列,但此法只能浅层复制。
- 字典 copy 方法,D.copy() 能够复制字典,但此法只能浅层复制
- 有些内置函数,例如 list,能够生成拷贝 list(L)
- copy 标准库模块能够生成完整拷贝:deepcopy 本质上是递归 copy
- 对于不可变对象和可变对象来说,浅复制都是复制的引用,只是因为复制不变对象和复制不变对象的引用是等效的(因为对象不可变,当改变时会新建对象重新赋值)。所以看起来浅复制只复制不可变对象(整数,实数,字符串等),对于可变对象,浅复制其实是创建了一个对于该对象的引用,也就是说只是给同一个对象贴上了另一个标签而已。
1 | L = [1, 2, 3] |
[1, 2, 3] {'a': 1, 'b': 2}
[1, 2, 3] {'a': 1, 'b': 2}
[1, 2, 3] {'a': 1, 'b': 2}
[1, 'NI', 3] {'a': 1, 'b': 2, 'c': 'spam'}
{'a': 1, 'b': {'a': 3}} {'a': 1, 'b': {'a': 3}}增强赋值以及共享引用
x = x + y,x 出现两次,必须执行两次,性能不好,合并必须新建对象 x,然后复制两个列表合并
属于复制/拷贝
x += y,x 只出现一次,也只会计算一次,性能好,不生成新对象,只在内存块末尾增加元素。
当 x、y 为list时, += 会自动调用 extend 方法进行合并运算,in-place change。
属于共享引用
深入理解 python 变量作用域及其陷阱
在python中,类型属于对象,变量是没有类型的,这正是python的语言特性,也是吸引着很多pythoner的一点。所有的变量都可以理解是内存中一个对象的“引用”,或者,也可以看似c中void*的感觉。所以,希望大家在看到一个python变量的时候,把变量和真正的内存对象分开。
类型是属于对象的,而不是变量。
这样,很多问题就容易思考了。
1 | nfoo = 1 #一个指向int数据类型的nfoo(再次提醒,nfoo没有类型) |
可变对象 & 不可变对象
- 在Python中,对象分为两种:可变对象和不可变对象,
- 不可变对象包括int,float,long,str,tuple等,可变对象包括list,set,dict等。
- 需要注意的是:这里说的不可变指的是值的不可变。对于不可变类型的变量,如果要更改变量,则会创建一个新值,把变量绑定到新值上,而旧值如果没有被引用就等待垃圾回收。另外,不可变的类型可以计算hash值,作为字典的key。
- 可变类型数据对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的内存地址会保持不变,但区域会变长或者变短。
1 | a = 'xianglong.me' |
函数值传递
1 | def ChangeInt( a ): |
这时发生了什么,有一个int对象2,和指向它的变量nfoo,当传递给ChangeInt的时候,按照传值的方式,复制了变量nfoo的值,这样,a就是nfoo指向同一个Int对象了,函数中a=10的时候,发生什么?(还记得我上面讲到的那些概念么),int是不能更改的对象,于是,做了一个新的int对象,另a指向它(但是此时,被变量nfoo指向的对象,没有发生变化),于是在外面的感觉就是函数没有改变nfoo的值,看起来像C++中的传值方式。
1 | def ChangeList( a ): |
当传递给ChangeList的时候,变量仍旧按照“传值”的方式,复制了变量lstFoo 的值,于是a和lstFoo 指向同一个对象,但是,list是可以改变的对象,对a[0]的操作,就是对lstFoo指向的对象的内容的操作,于是,这时的a[0] = 10,就是更改了lstFoo 指向的对象的第一个元素,所以,再次输出lstFoo 时,显示[10],内容被改变了,看起来,像C++中的按引用传递。
1 | def func_list(a_list): |
这主要是由于=操作符会新建一个新的变量保存赋值结果,然后再把引用名指向=左边,即修改了原来的p引用,使p成为指向新赋值变量的引用。而+=不会,直接修改了原来p引用的内容,事实上+=和=在python内部使用了不同的实现函数。
同样
1 | list_a = [] |
因为 = 创建了局部变量,而 .append() 或者 .extend() 重用了全局变量。
为什么修改全局的dict变量不用global关键字
为什么修改字典d的值不用global关键字先声明呢?
1 | s = 'foo' |
这是因为,在s = ‘bar’这句中,它是“有歧义的“,因为它既可以是表示引用全局变量s,也可以是创建一个新的局部变量,所以在python中,默认它的行为是创建局部变量,除非显式声明global,global定义的本地变量会变成其对应全局变量的一个别名,即是同一个变量。
在d['b']=2这句中,它是“明确的”,因为如果把d当作是局部变量的话,它会报KeyError,所以它只能是引用全局的d,故不需要多此一举显式声明global。
上面这两句赋值语句其实是不同的行为,一个是rebinding(不可变对象), 一个是mutation(可变对象).
但是如果是下面这样:
1 | d = {'a':1} |
在d = {}这句,它是”有歧义的“了,所以它是创建了局部变量d,而不是引用全局变量d,所以d['b']=2也是操作的局部变量。
推而远之,这一切现象的本质就是”它是否是明确的“。
仔细想想,就会发现不止dict不需要global,所有”明确的“东西都不需要global。因为int类型str类型之类的不可变对象,每一次操作就重建新的对象,他们只有一种修改方法,即x = y, 恰好这种修改方法同时也是创建变量的方法,所以产生了歧义,不知道是要修改还是创建。而dict/list/对象等可变对象,操作不会重建对象,可以通过dict[‘x’]=y或list.append()之类的来修改,跟创建变量不冲突,不产生歧义,所以都不用显式global。
陷阱:使用可变的默认参数
我多次见到过如下的代码:
1 | def foo(a, b, c=[]): |
永远不要使用可变的默认参数,可以使用如下的代码代替:
1 | def foo(a, b, c=None): |
与其解释这个问题是什么,不如展示下使用可变默认参数的影响:
1 | In[2]: def foo(a, b, c=[]): |
同一个变量c在函数调用的每一次都被反复引用。这可能有一些意想不到的后果。