我们有时候自己需要构建数据集,而在 torch 中,也给我们制定了相关的规范。
pytorch读取训练集是非常便捷的,只需要使用到2个类:
torch.utils.data.Dataset
torch.utils.data.DataLoader规范代码
You should build your custom dataset as below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class CustomDataset (torch.utils.data.Dataset) : def __init__ (self) : pass def __getitem__ (self, index) : pass def __len__ (self) : return 0
You can then use the prebuilt data loader.
1 2 3 4 custom_dataset = CustomDataset() train_loader = torch.utils.data.DataLoader(dataset=custom_dataset, batch_size=64 , shuffle=True )
例子 (自定义数据集)
这个例子来源于知乎
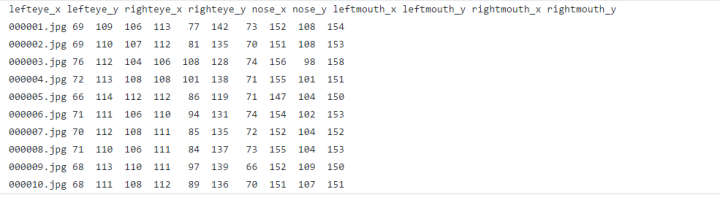
假设我们有一个标签test_images.txt,内容如下:
对应的图像位于images目录下。
首先要继承torch.utils.data.Dataset类,完成图像及标签的读取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import osimport torchimport torch.utils.data as datafrom PIL import Imagedef default_loader (path) : return Image.open(path).convert('RGB' ) class myImageFloder (data.Dataset) : def __init__ (self, root, label, transform = None, target_transform=None, loader=default_loader) : fh = open(label) c=0 imgs=[] class_names=[] for line in fh.readlines(): if c==0 : class_names=[n.strip() for n in line.rstrip().split(' ' )] else : cls = line.split() fn = cls.pop(0 ) if os.path.isfile(os.path.join(root, fn)): imgs.append((fn, tuple([float(v) for v in cls]))) c=c+1 self.root = root self.imgs = imgs self.classes = class_names self.transform = transform self.target_transform = target_transform self.loader = loader def __getitem__ (self, index) : fn, label = self.imgs[index] img = self.loader(os.path.join(self.root, fn)) if self.transform is not None : img = self.transform(img) return img, torch.Tensor(label) def __len__ (self) : return len(self.imgs) def getName (self) : return self.classes
关于 transform ,你可以看我的另一篇博客
pytorch | torchvision transform 的讲解
实例化torch.utils.data.DataLoader 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 mytransform = transforms.Compose([ transforms.ToTensor() ] ) imgLoader = torch.utils.data.DataLoader( myFloder.myImageFloder(root = "../data/testImages/images" , label = "../data/testImages/test_images.txt" , transform = mytransform ), batch_size= 2 , shuffle= False , num_workers= 2 ) for i, data in enumerate(imgLoader, 0 ): print(data[i][0 ]) img2 = data[i][0 ].numpy()*255 img2 = img2.astype('uint8' ) img2 = np.transpose(img2, (1 ,2 ,0 )) img2=img2[:,:,::-1 ] cv2.imshow('img2' , img2) cv2.waitKey() break
使用 torch 公有例子
对于常用数据集,可以使用torchvision.datasets直接进行读取。torchvision.dataset是torch.utils.data.Dataset的实现
下面以cifar10为例:
1 2 3 4 5 6 7 8 9 10 11 import torchimport torchvisionfrom PIL import ImagecifarSet = torchvision.datasets.CIFAR10(root = "../data/cifar/" , train= True , download = True ) print(cifarSet[0 ]) img, label = cifarSet[0 ] print (img)print (label)print (img.format, img.size, img.mode)img.show()
实例化torch.utils.data.DataLoader 1 2 3 4 5 6 7 8 mytransform = transforms.Compose([ transforms.ToTensor() ] ) cifarSet = torchvision.datasets.CIFAR10(root = "../data/cifar/" , train= True , download = True , transform = mytransform ) cifarLoader = torch.utils.data.DataLoader(cifarSet, batch_size= 10 , shuffle= False , num_workers= 2 )
下面就可以进行读取数据的显示,以进行简单测试是否读取成功:
1 2 3 4 5 6 for i, data in enumerate(cifarLoader, 0 ): print(data[i][0 ]) img = transforms.ToPILImage()(data[i][0 ]) img.show() break