这是fildder的基础。
参考资料
抓包工具的比较

抓包工具详解
file
edit

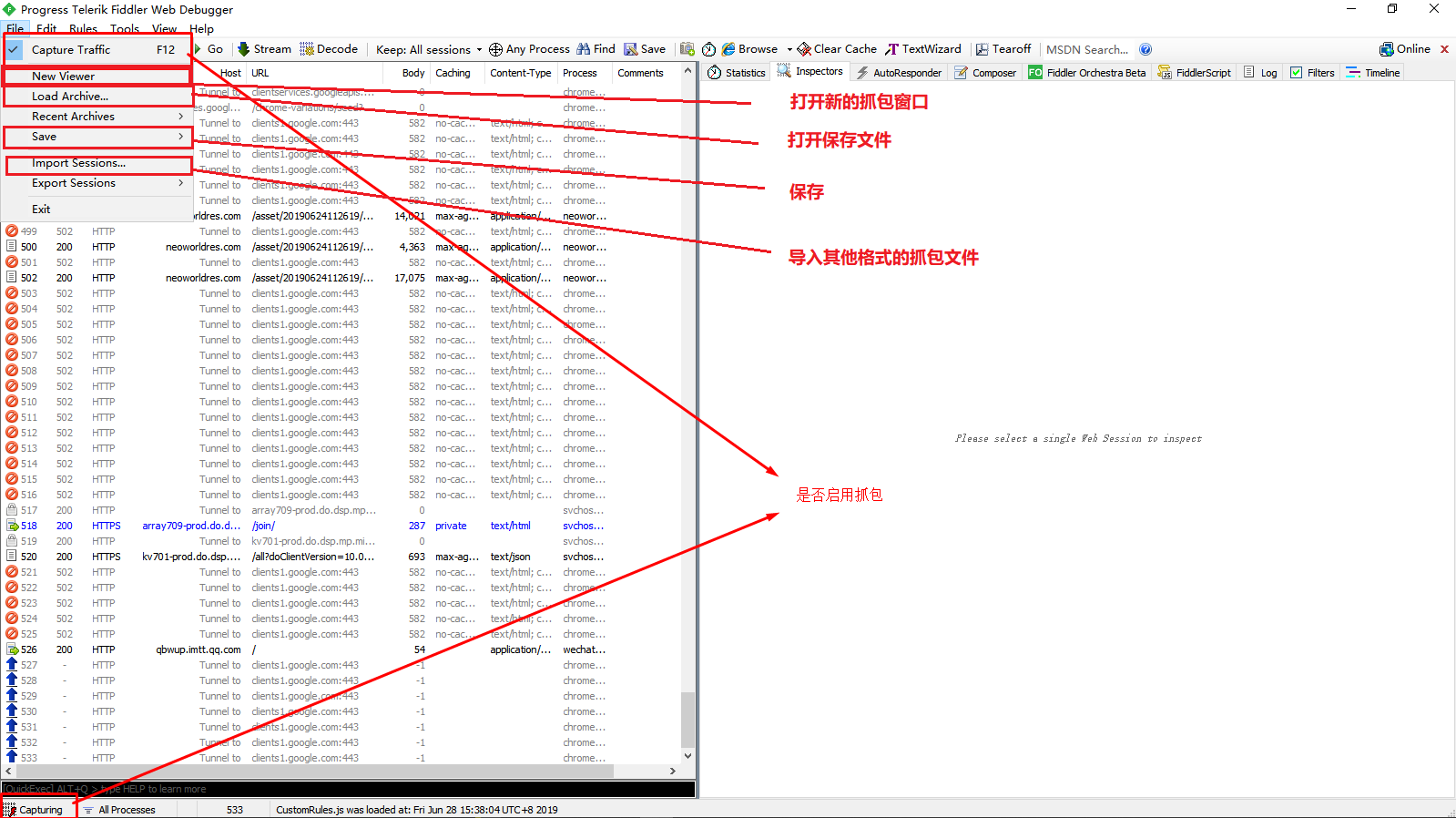
当我们选择一个包之后,点击edit——>Unlock for Editing,我们就能抓取包了。这个时候被unlock的包的前面的小标识就会变成一个笔在纸上。
我们选择右边包信息的Inspectors的Raw选项,在哪里我们就可以直接更改包信息,更改完包信息,我们再点击Unlock for Editing这个包就会更改完成。
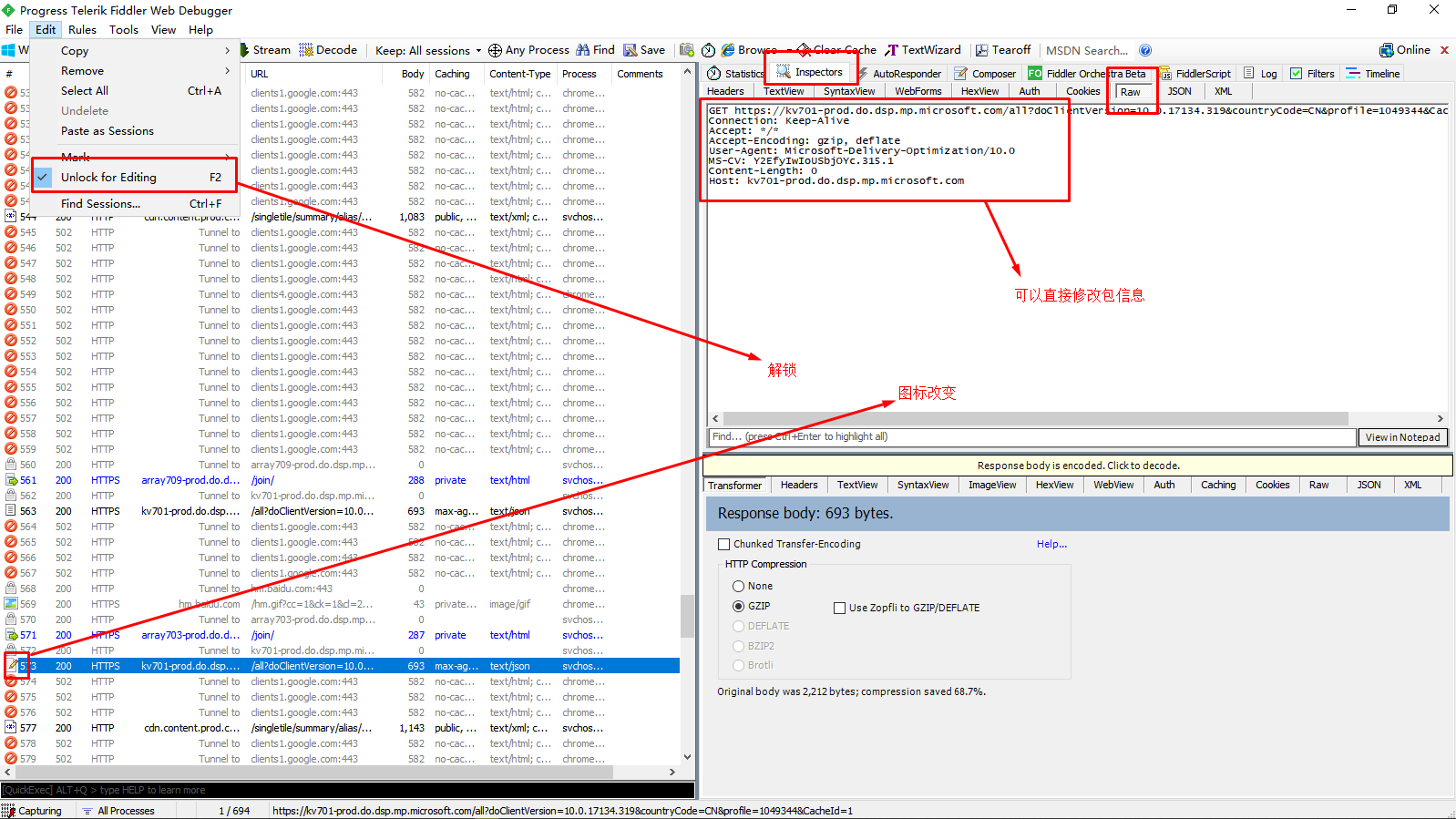
在edit中有一个选项是Find Sessions,通过这个可以实现session的查询,也可以通过修改不同的颜色来查找,还有严格匹配模式和正则匹配模式。
tools
options
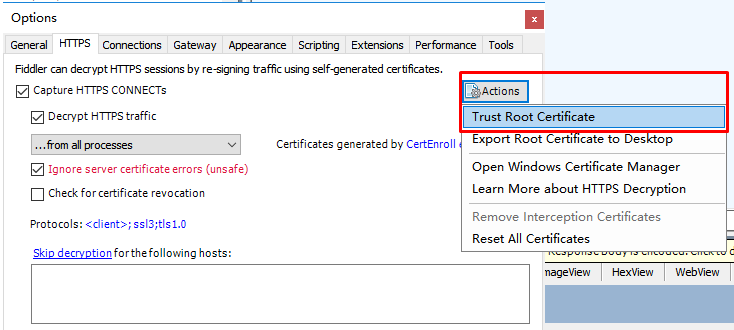
HTTPS
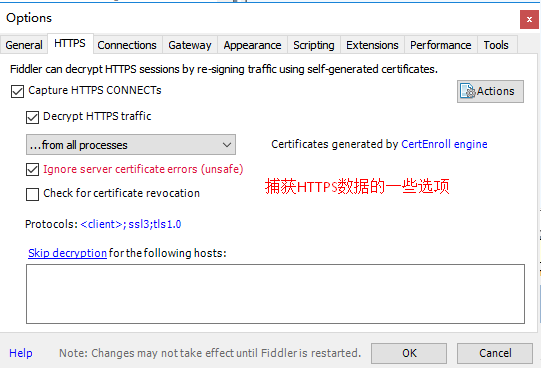
安装证书,让电脑信任fildder,使得其可以作为中间人,来获取信息。安装证书的时候一直YES就可以了。
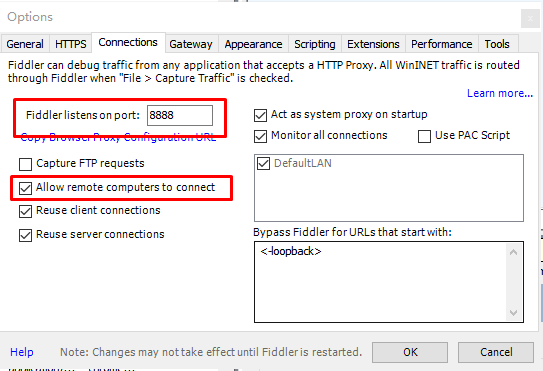
Connections
设置端口
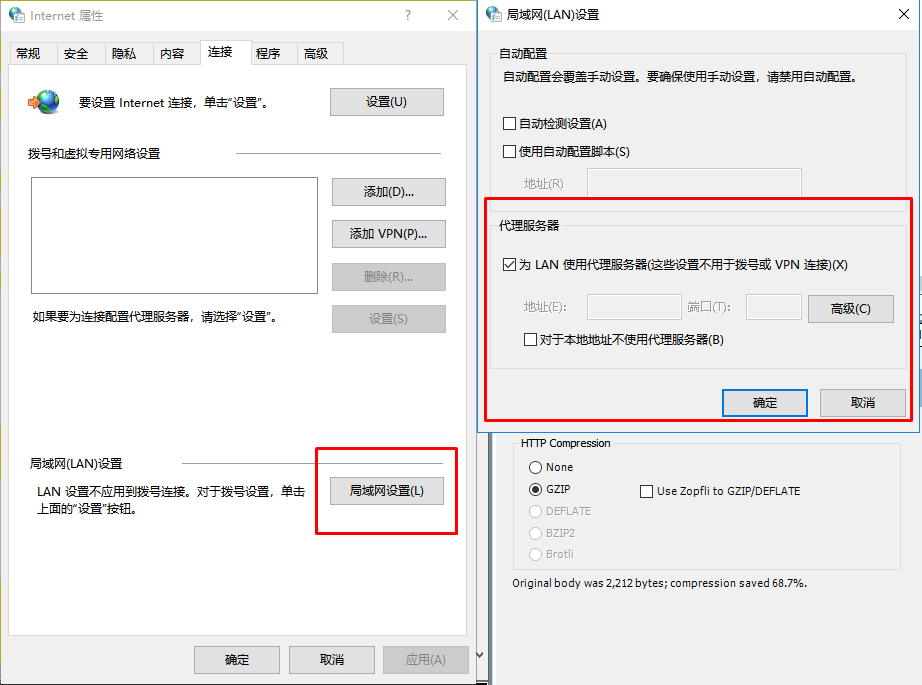
WinINET options
如果没有代理软件,这个选项是可以设置本地电脑的代理,让fildder走这个代理服务器。
Clear WinINET cache/cookies
这是清理电脑缓存。
TextWizard
这是一个编码转换工具。

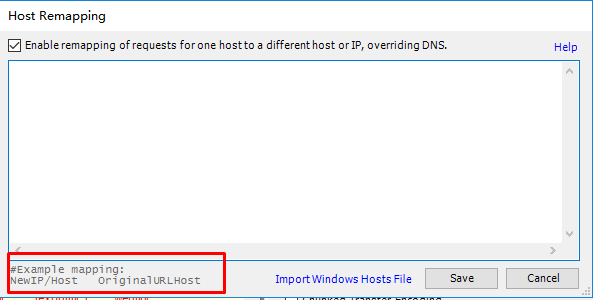
HOSTS
电脑文件都有一个HOSTS文件,电脑在访问网址之前,都会经过这个文件,但是,每次修改起来太麻烦了,所以,这个HOSTS可以让你暂时性的起到HOSTS文件的作用。
Rules
Hide Image Requests
隐藏所有的Image请求
Automatic Breakpoints
自动打断点,这里有图片模式,也有命令行模式,一般命令行模式更加方便,这个也只介绍命令行模式。
Performance
Simulate Modem Speeds
慢速访问,之前的访问都是正常速度,选择了这个选项之后,就会速度变慢来访问网页。
Disable caching
关闭缓存
Cache Always Fresh
缓存实时刷新
工具栏

1
这是一个注释,点击某一个session后,再点击它,就能够做注释了,出现在session的comments中。
2
这个流重放,点击session然后点击replace,就会重新访问这个session。
3
这个是选择性删除
4
执行模式,这个是和截获包,然后修改包之后,执行的。
5
流模式。
在fildder中有两种模式,一个是流模式,一个是缓存模式,流模式是实时抓包的展示模式。
图中的那个就是流模式。
缓存模式是加载完之后才会展示。
6
是解析我们的数据流,如果不选择 Decode 那就得手动解密。
7
这个是根据电脑配置来的,一次性加载多少个sessions。
8
这个是抓取专门的进程的,鼠标点击它,就会成为一个十字标,然后十字标点击正在运行的进程,就会只抓取那个进程的数据包。
11
清除缓存。
会话列表(请求头、响应头)


断点设置
命令行
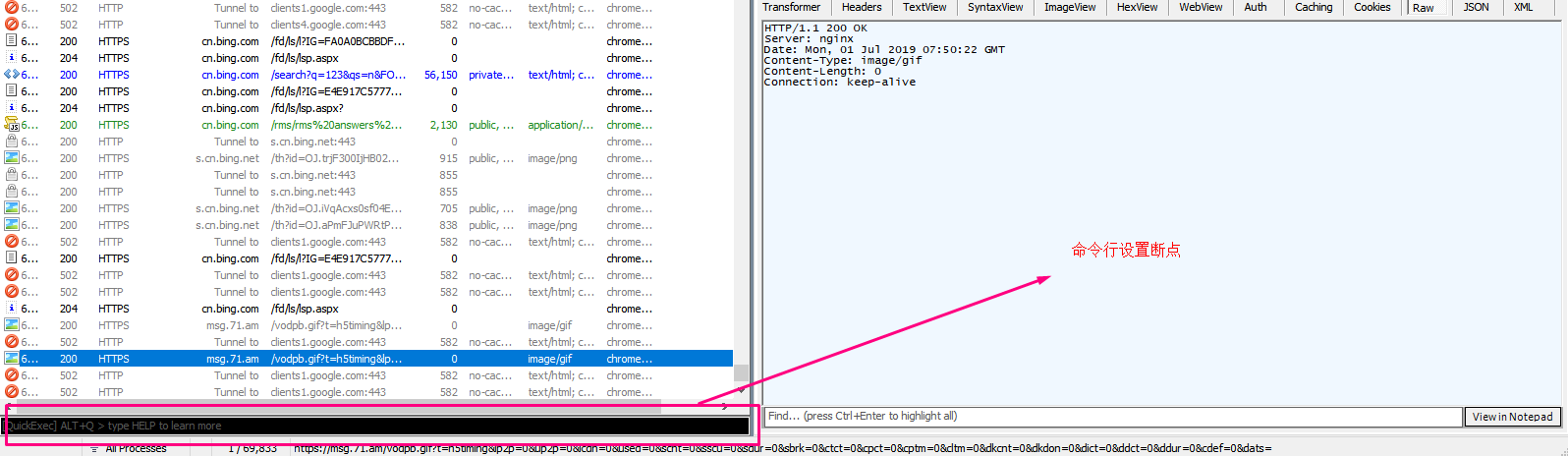
请求前的拦截
在命令行中输入
bpu 网址
bpu https://www.baidu.com 
然后点 enter ,breakpoint的字样就会出现在下面。

当我们在百度搜索的时候,就会在 sessions 界面出现红色打岔上传。
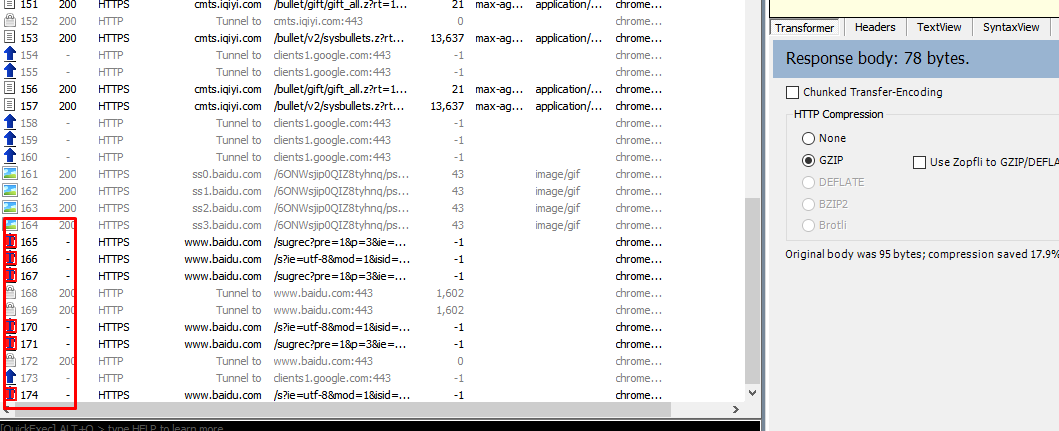
里面一共有6个叉,其实一共有用的只有两个,另外的叉是百度的特性导致的。
比如,你要搜索 123 ,当你输入 1 的时候,百度就开始上传了,然后 12 的时候,百度又开始上传,所以,我们可以看到有 6 个叉。
但是,只得注意的是我们需要找最后两个数据包,并且更改才有用。但是,并不是最后两个数据包就是我们要找的数据包,具体的还得读数据。
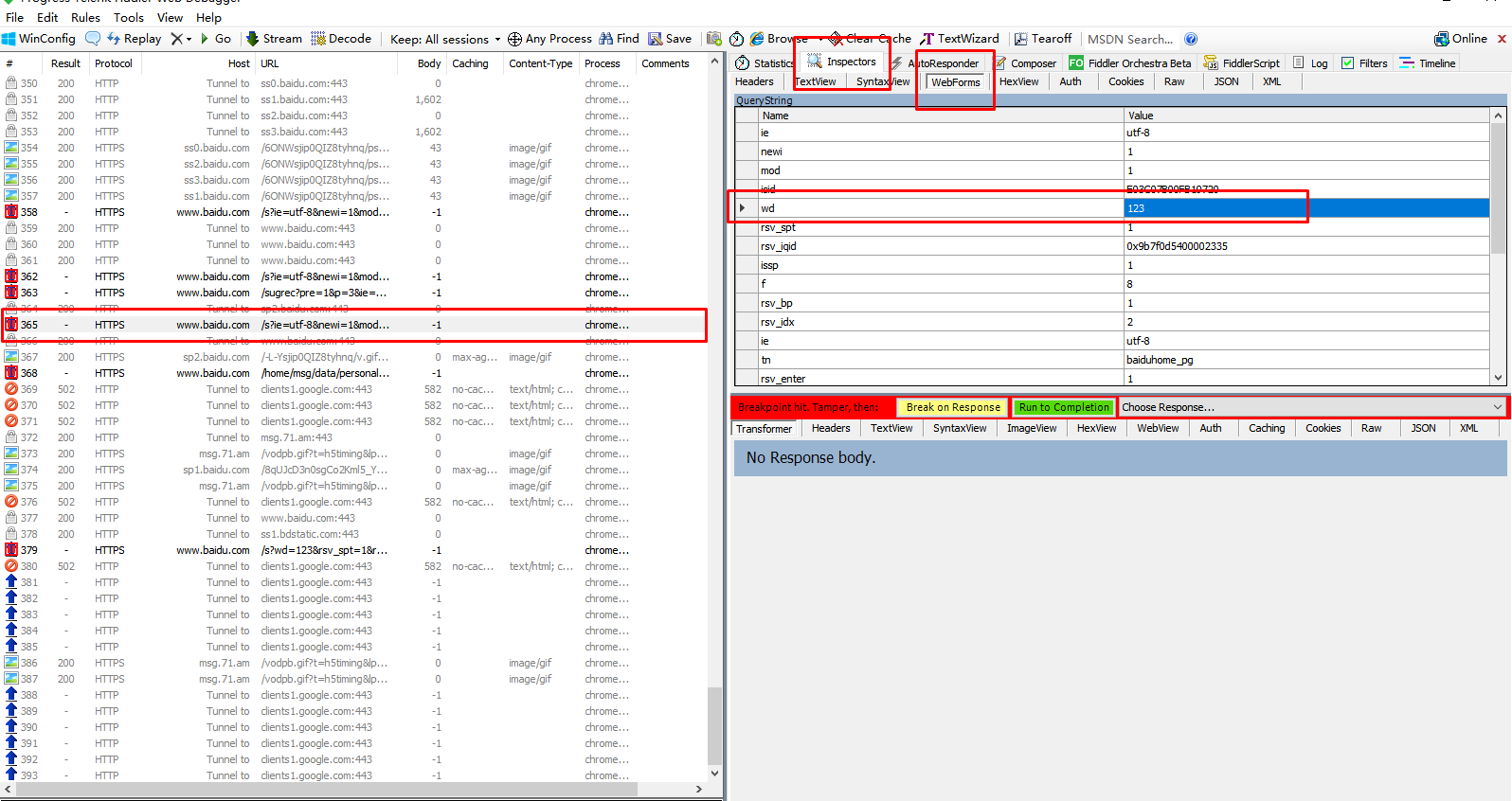
寻找到那个包之后,找到其中一个包,修改 wd (也就是关键词)
然后将这个 wd 修改成 python ,然后点击 break on response ,将修改的包传到下面的那个包。
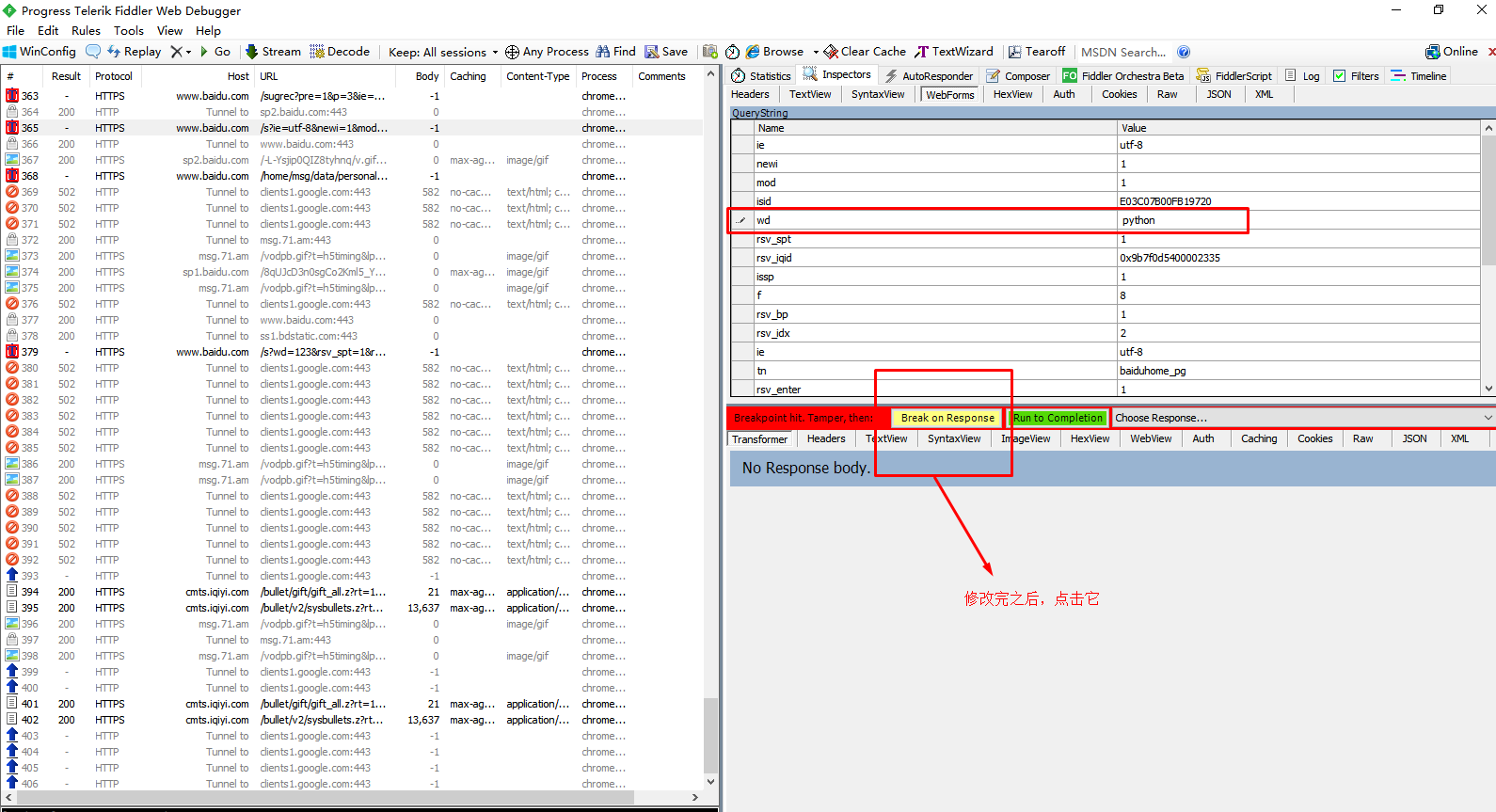
只修改一个包是改变不了的,这有可能和百度的机制有关,我也不太清楚。
找到下一个加载包,同样修改 python ,然后点击 break on response。
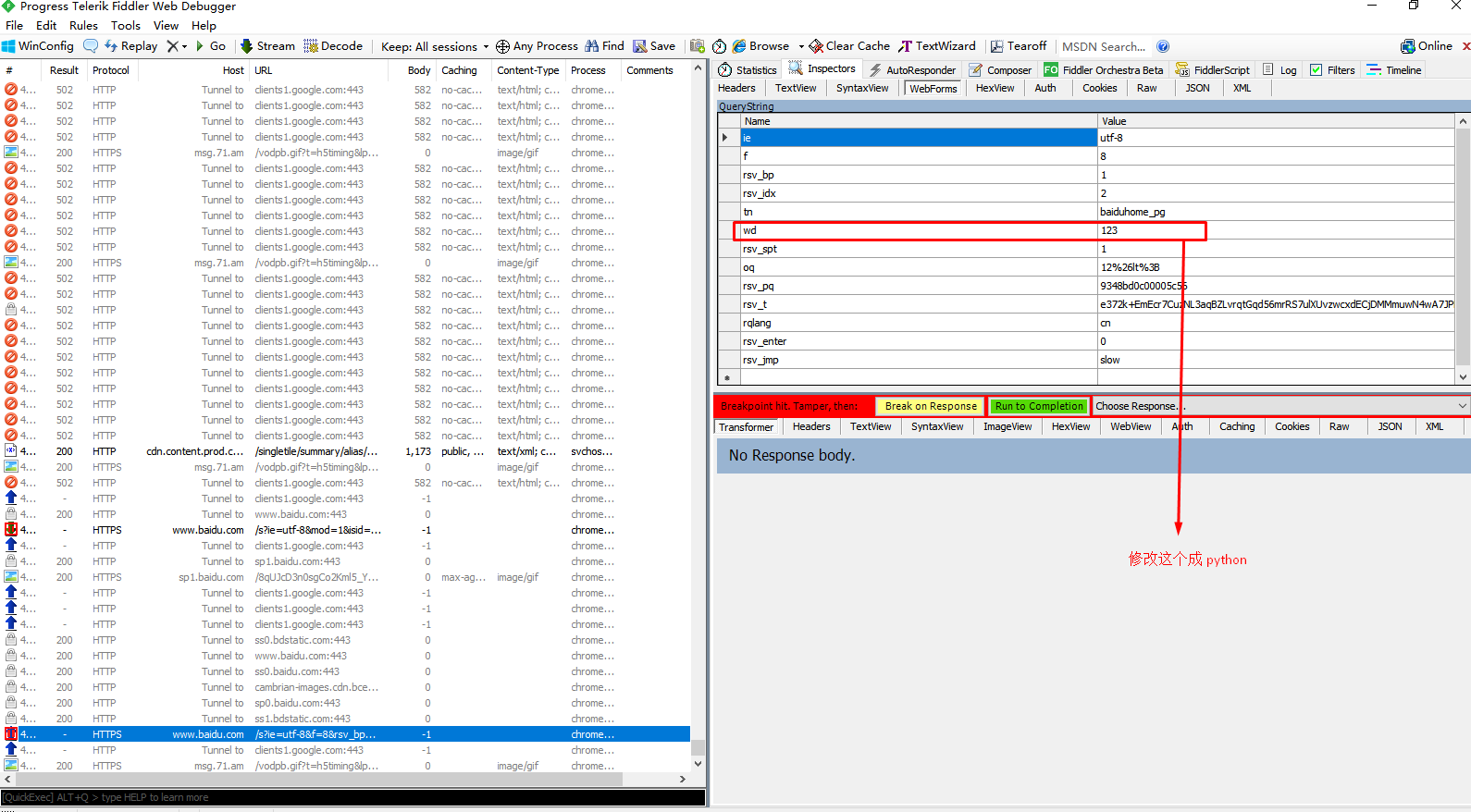
这里有一个细节,就是点击了 break on response 的session 其上传断点的标志会变成下传断点的标志。
当两个都修改,并点击完 break on response 后,找到第一个 session 包,点击 run to conpletion,这个时候百度的页面已经变成了搜索 python 。
但是,这个时候并没有全部完成,也就是页面还在加载。需要点击另一个包的 run to conpletion。
取消断点
取消断点只需要在命令行中输入 bpu 即可。
响应包的拦截
bpafter 网址在命令行中输入:bpafter https://www.baidu.com
然后,将数据包选择回复方式。

选择 404 后,然后点击 run to conpletion ,奇怪的是,我得点击两次才行。

取消响应包
bpa网页的重定向
这一小节,我将把百度的小标变成我的图片。

把这个ico进行编辑。
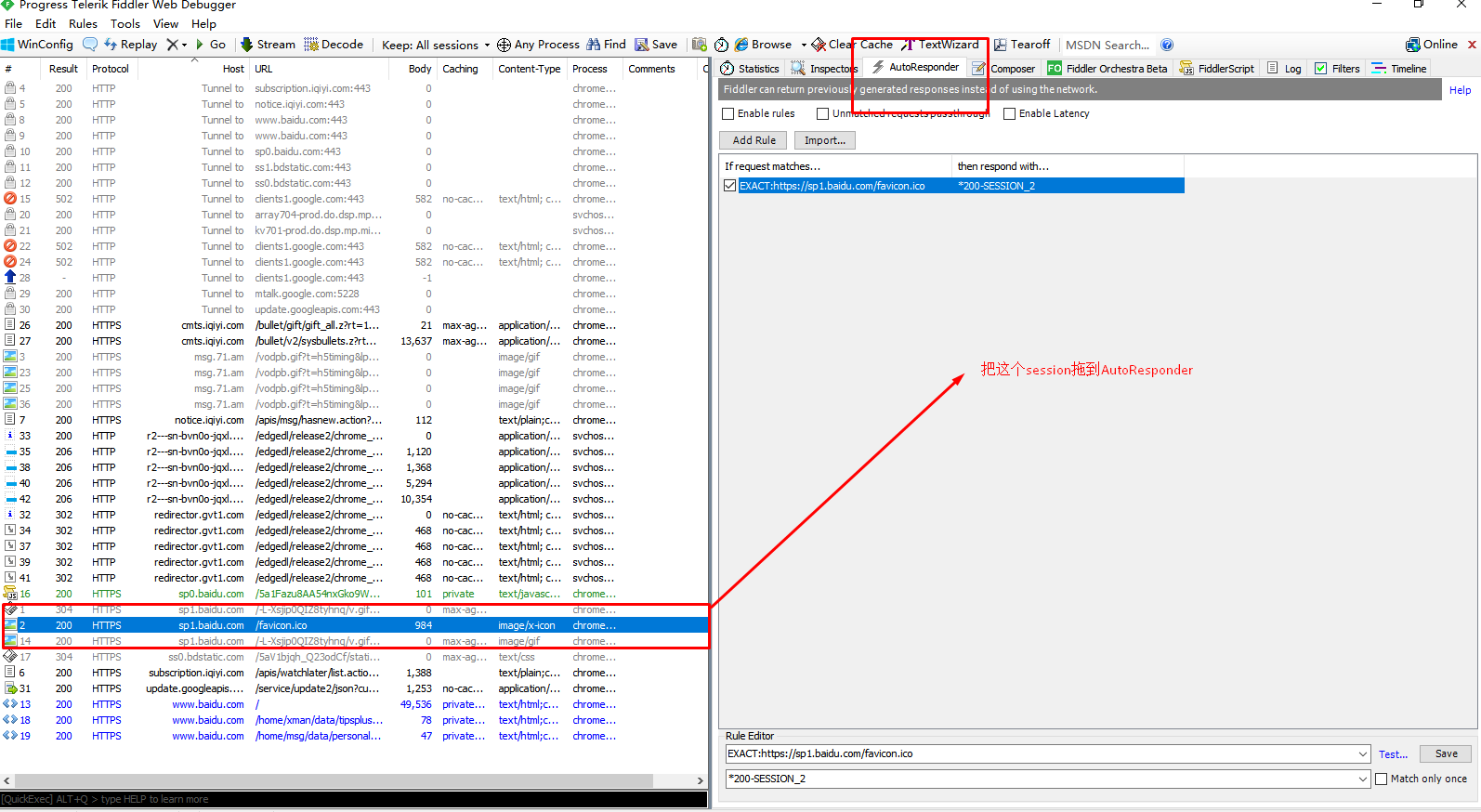
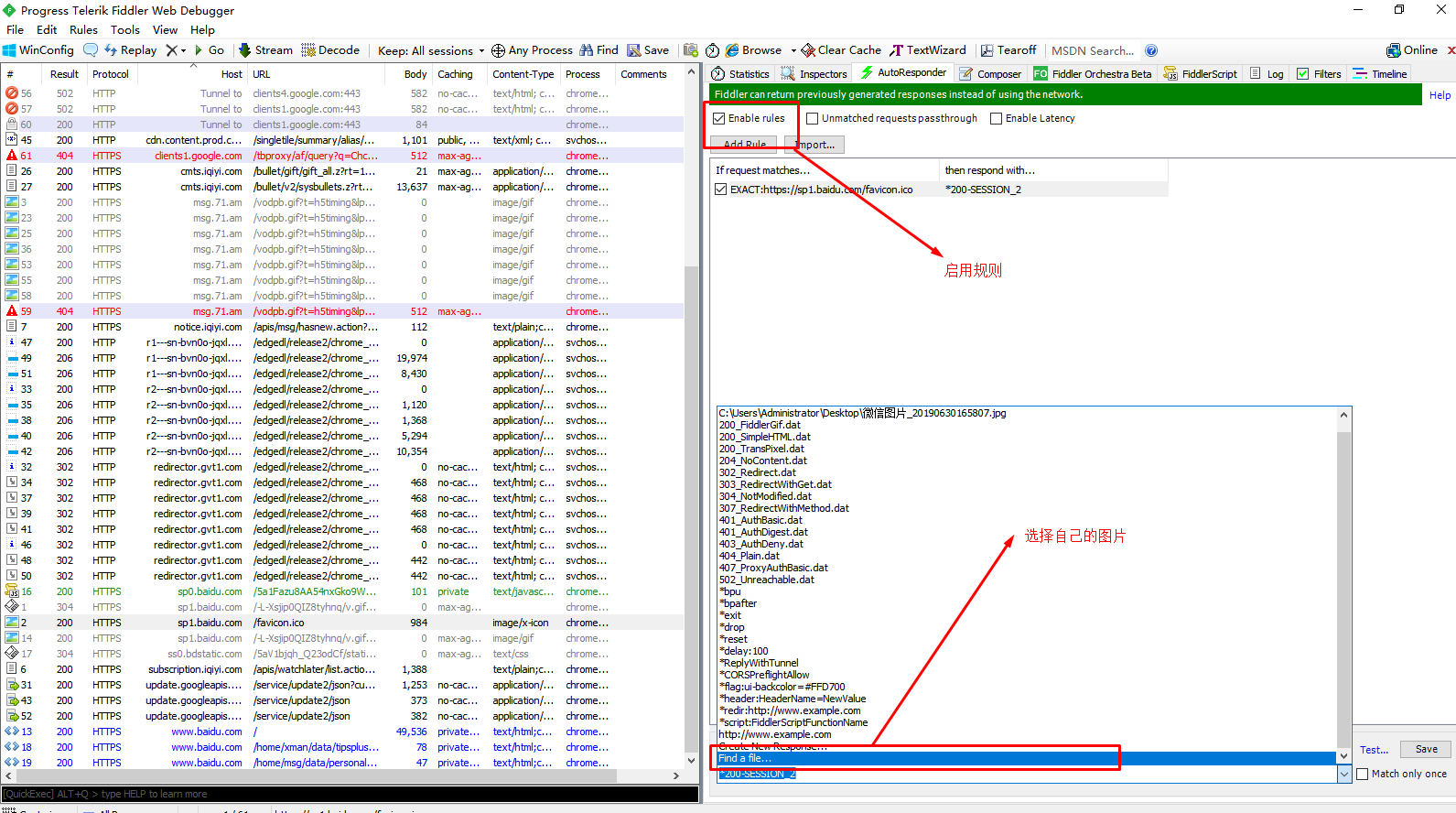
选择完图片后,点击save,刷新页面。

这个例子有一点小瑕疵,效果没有展现出来,但是流程是这样的。
安装代理工具
视频中安装了一个 chrome 的插件,switchy omega,用来设置代理。
但是,我在别的地方了解到 chrome 的代理默认是和系统相同的,这和火狐独立代理不一样,所以,不需要设置代理插件,在以后的使用过程中,确实如此。
而且,我用的是APP爬虫,所以,本身也就没有这个需求。