这里介绍一下 scrapy 的基础。
看之前的说明
因为这个教程的是在用 anaconda 前的教程,所以,各方面都有点滞后,所以,如果安装了 anaconda 的用户,应该能更快的安装配置环境。
scrapy安装
创建相关的虚拟环境后,用豆瓣源
pip install -i https://pypi.douban.com/simple/ scrapy
但是在安装过程中twisted可能会出错
所以要到官方网站
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载适合自己的版本的twisted.whl
安装完之后,放在任意一个路径即可
进入虚拟环境,执行
pip install D:\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
自主安装twisted
在执行pip install -i https://pypi.douban.com/simple/ scrapy
成功后 输入scrapy -h 检验是否安装成功
如果有了 anaconda 的话,上面这些事非常好安装的其实scrapy是一个框架,但不是引进去,需要用下载的scrapy单独创建一个scrapy项目,后续代码需要在这个项目中写
选取一个路径,将项目创建到这个路径下
首先在正常模式下,进入要创建的项目路径内
启动相关虚拟机(这个启动相关虚拟机其实是根据 virtualenvwrapper 来的,但是由于用的是 anaconda ,所以一开始就应该进入虚拟环境,事实上即便是 virtualenvwrapper 也要一开始就进入虚拟环境)
输入命令 scrapy startproject Article (Article 是我们要创建的项目名字)
项目创建成功scrapy项目下的文件夹用途
spiders文件夹里面是存放具体的某个爬虫
但是里面的文件是空的,所以可以创建一个要爬的域名项目
进入到创建好的项目下面 cd... (否则后期创建文件会放在其他目录下面)
输入命令scrapy genspider 项目名(域名) 域名路径
scrapy genspider baidu baidu.com
会创建一个项目名.py文件创建完文件后,需要配置虚拟环境的解释器,否则会用默认的全局解释器,额,这个解释器就是 pycharm 的解释器配置。
实际上,我更喜欢用 anaconda 的 prompt
具体如下
file-setting-输入interp-找到project interpreter
在右框中选择虚拟环境中的python.exe文件,在相关虚拟环境下的scrapys目录下以上配置完成,可以直接写代码了
启动scrapy,爬取
输入命令 scrapy crawl 项目名(都要在虚拟环境的相关目录下进行)
额,让我来更加具体的说明一下,你创建了一的目录,名字为 spider ,然后你进入这个目录后
执行
scrapy startproject test
于是,再 spider 的目录下,你就多了一个 test 目录,当你完成基础配置,并且编写完代码之后,你需要进入
***/spider/test 这个路径下面
然后执行
scrapy crawl 项目名
这个项目名也就是爬虫名
即为spiders文件夹下,你所创建的一个爬虫类中,name属性的值
win可能会缺少win32api文件,只需要在pip install pypiwin32在豆瓣源下下载即可
当然启动项目这条命令可以配置到相关文件中,省去输入这条步骤from scrapy.http import Request
用于请求参数
爬虫编写
建立项目后
定义 Item 容器
用于保存爬取到的数据的容器,其使用方法和python的字典类似,并提供了额外保护机制来避免拼写错误导致的未定义字段错误编写爬虫
编写爬虫类 Spider,在spiders文件夹下的你创建的文件中。
Spider是用户编写用于爬网站的类
其中包含一个用于下载的初始URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法 存储内容
存取主要是 piplines.py 的工作工作流程
调用
scrapy crawl 爬虫名从互联网中爬取数据即 response ,我们再对 response 做处理
然后爬虫类中 parse 方法,分析数据
再将其用 item 容器保存
再做后续处理,比如存储等等
我所理解的 scrapy
Scrapy 是一个框架,当建立好一个 scrapy 的项目的时候,里面有诸多文件。

事实上,数据的流向都是经过 Engine ,当我们传递给第一个 URL 给 Engine 的时候, Engine 会将这个参数传递给 Downloader 进行下载,这些都是自主完成的。 Downloader 会自己下载第一个 URL 的页面内容,并返回给 spiders文件夹下的 spider文件中的爬虫类。

上面的是setting 中的参数值,这些值,在你创建项目的时候就已经生成了,这三项参数告诉你,项目名是什么,爬虫类在哪个地方
而 spiders 文件夹下面的有一个文件,即init.py,这是默认生成的,一般不需要改,只需再创建一个py文件,这个文件中写爬虫类。
所谓的爬虫类,就是对下载下来的数据进行处理。
下面就是一个爬虫类例子:
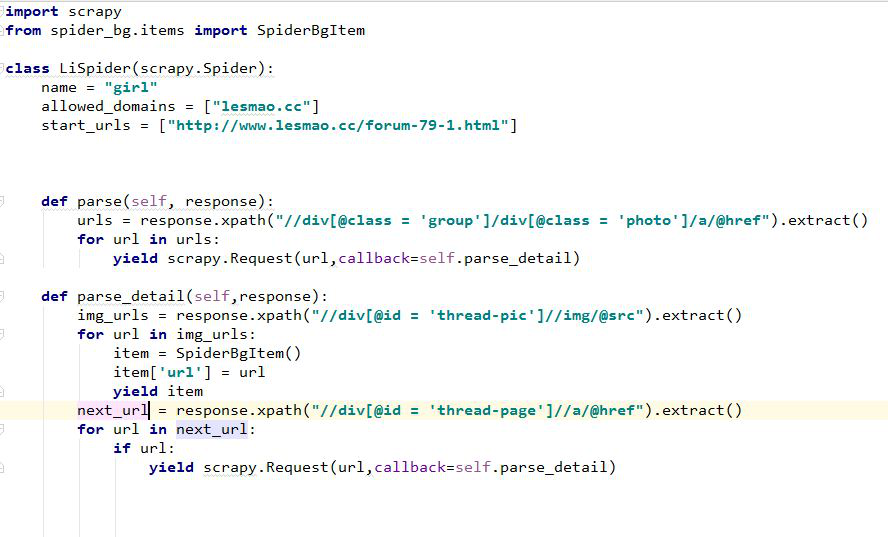
在我们定义的 class 中,有三个静态属性,name,allowed_domains,start_urls
name 是定义爬虫的名字 在命令行中启动爬虫时就是 scrapy crawl 爬虫名
Allowed_domains 是叫爬取的范围,假如不是这个域名,则不会爬取
Start_urls 是要爬取的第一个url上面这三个参数是必须的
第一个url交给 Engine ,engine 再交给 downloader ,进行下载,下载的内容交给爬虫类中的parse 方法中的 response 参数 ,我们在对 response 的参数进行处理。
我们会将 response 中的内容分成两个部分,第一,我们要获取的数据,第二,我们需要再次爬取的 url ,如下一页等等
首先处理已经获取的数据,我们要存储数据,必须经过两个部件,数据经过 items 中的文件类进行包装,传递给 engine ,然后engine 再交给 pipelines 文件进行存储操作。
Items 中的文件类需要预先定义,它的作用是对需要存储的数据,进行格式化,类似字典,但不是字典,需要注意的是对 yield 的运用,具体可看图中的代码
而 pipelines 是对数据进行后处理,如存储,首先,这个 pipelines 是一个管道文件,但这个管道文件,在 setting 中是默认关闭的,所以我们要开启它
如下图

这个属性是告诉 scrapy 有一个管道是在spider_bg文件夹下,pipelines 文件的SpiderBgpipeline 类中,其优先值为300,优先值越低,优先级越高
Pipelines 文件如下图:
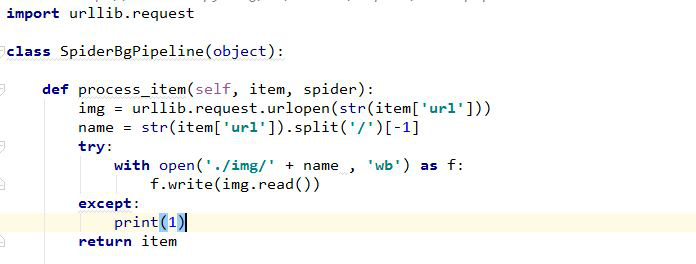
事实上,我们可以设立多个管道文件,只需要在 setting 文件中添加相关属性即可,假如设置了不同相关级别的管道类,目的是分开处理图片呢和文字,engine 会将已经格式化的 items 优先传递给优先级高的管道,处理完后,再传给优先级低的管道,直到所有的管道都已经传递完,再返回 爬虫类。
而对于另外的 url 如下一页等等怎么处理,可以参考图片中爬虫类的代码。
一个完整的项目组建过程
我们建立了一个目录,名为 spider
然后进入这个目录,执行下面的命令
scrapy startproject spider我们的目录就变成下面这样
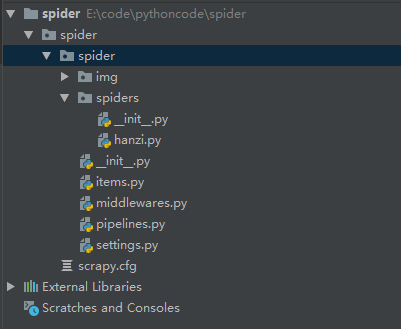
原来在 spiders 下面是没有 hanzi.py 文件的,所以,我们要进入这个目录的路径下
执行
scrapy genspider hanzi cidianwang.com这样就在这个目录下面出现 spiders.py
我们的项目需求如下:

我们需要下载文征明的所有字体图片,其中包括隶书,行书等,但是要获取更多字体图片的话,我们必须点击“更多”
如下

所以,我们的需求就是,获得各种字体的入口,然后在获取字体页面的所有图片,点击下一页,继续获取所有图片。
因为,所有字体的总入口在
http://www.cidianwang.com/shufa/wenzhengming2910.htm所以,我们编写 spiders 目录下的 HanziSpider 这个 class ,其中 parse 是解析函数,是函数的总入口。
所以, spiders 下的 hanzi.py 的内容如下
1 | # -*- coding: utf-8 -*- |
我们编写 items 文件,这个文件主要是规定文件的格式
所以, items.py 内容如下
1 | # -*- coding: utf-8 -*- |
然后,我们编写存储文件,即 pipelines.py 文件
1 | # -*- coding: utf-8 -*- |
OK,到了现在一个很简易的爬虫就做好了,虽然爬虫非常简单,但是,已经可以适应大部分的网站了。
我们进入到虚拟环境,然后切换路径到你的项目,对于此例便是
***/spider/spider然后,我们就输入
scrapy crawl hanzi 就可以愉快的下载了,效果如下图:
