如题所示。
C
conv2d()
Tensorflow初学笔记——tf.nn.conv2d的工作方法
函数定义
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
功能:在给定4-D 输入和fliters的情况下,计算二维卷积。
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一,通道数实际上是输入图片的三维矩阵的深度,如果是普通灰度照片,通道数就是1,如果是RGB彩色照片,通道数就是3,当然这个通道数完全可以自己设计。
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维,其中长和宽指的是本次卷积计算的“抹布”的规格,输入通道数应当和input的通道数一致,输出通道数可以随意指定。
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4,一般情况下的格式为[1,长上步长,宽上步长,1],所谓步长就是指抹布(卷积核)每次在长和宽上滑动多少会停下来计算一次卷积。这个步长不一定要能够被输入图片的长和宽整除。
第四个参数padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map
tensorflow中构建CNN最主要的函数之一就是conv2d(),它是实现卷积计算的核心步骤函数.
首先,卷积的意思就是从图像的像素点上抽象出特征,然而这个特征抽取的过程并不是传统意义上的人工的抽取,而是通过卷积核进行自动抽取,当然这种抽取的结果对于人类来说也很难讲有什么能够解释的意义。数字图像(比如说一张照片),可以看做是一个矩阵,每一个像素点都是矩阵中的一个元素:特别的,如果照片是黑白的,那么可以看做是一个length×width×1的三维矩阵;如果是彩色的(比如RGB)那么就可以看做一个length×width×3的三维矩阵。卷积核像一小块方形的抹布,在图片上由上到下从左到右均匀抹过,并不时的停下来,当抹布停下来的时候,抹布上的点就会和其覆盖的点进行计算,得到一个值,这个值就将成为卷积计算输出矩阵的对应点的值。
从直观上看,卷积的过程相当于将图片“浓缩了”,当然在浓缩的过程中,厚度是可以变的。
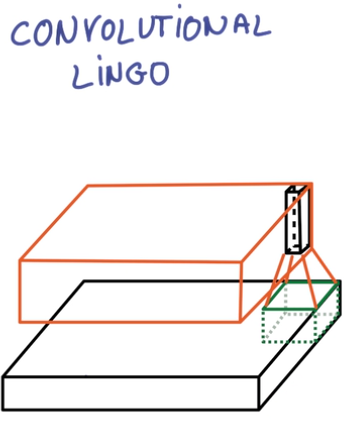
上图中,黑色的板子就是输入的图片,橙色的板子就是卷积“浓缩”后的图片,绿色的小色块就是卷积核,也就是“抹布”。当然,如果抹布能做到一步一停并且采用“same”模式的话,那么浓缩后的大小就不会变。值得注意的是,卷积之后的结果厚度是用户自己指定的,至于说这个厚度有什么意义,我的理解是:厚度的每一层都类似于某一频率和振幅的正弦波,而多个不同的正弦波理论上讲是可以拟合任意复杂的波形,所以多种不同的卷积结果,理论上也能够拟合比较复杂的特征提取方案的。
对于 padding 的模式讲解
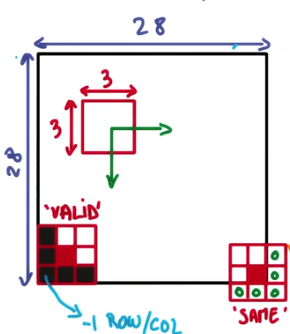
可以看到,valid模式在边缘采取的是“不及”的方法,而same则是“过”的策略,两者效果孰优孰略取决于你的数据在边缘有没有什么重要信息。
那么具体的卷积方法用一个实例来解释:
1.输入的数据是[100,80,100,4]的数据,经过的卷积核是[8,8,4,32],步长为[1,4,4,1]策略是valid,那么首先输入的batch=100是不会变的,深度4要变成输出的32,输入图片长度80要在长为8的卷积核下以步长4划过一次,那么抹布的右边缘所处的像素点横坐标应当依次是8,12,16,20……80一共19次计算,所以输出结果的长应当是19,同理,输出结果的宽应当是24,因此输出结果的形状应当是[100,19,24,32]
2.将第一步的结果输入卷积核[4,4,32,64],步长调整为[1,2,2,1],模式依旧是valid,那么输出结果是[100,8,11,64]
3.将第二步的结果输入卷积核[3,3,64,128],步长调整为[1,1,1,1],模式调整为same,那么输出结果是[100,8,11,128]
实际处理
在实际的运算中,计算机实际上首先将输入的input数据规模上进行拓展,由原来的
[batch,length,width,channel_in]转化为[batch,out_length,out_width,filter_length×filter_width×channel_in]的格式
其中所谓输出的长宽是通过卷积核的长宽和卷积模式计算好的,一般来讲,卷积过程中卷积核的抽象区域应当有重叠而不应当有缝隙,所以大多数情况下,这样变形的结果是输入数据从规模上被扩大了。而此时,需要进行计算的卷积核矩阵也被变形成[filter_length×filter_width×channel_in,channel_out]的格式,虽然从规模上来说矩阵的大小没变,但是从维度上来说,卷积核被从4维拍扁成了两维,两个变形后的矩阵相乘,得到的结果就是[batch,out_length,out_width,channel_out]了。
D
dropout
tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层。
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。示意图如下:

函数说明
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
上面方法中常用的是前两个参数:
第一个参数x:指输入
第二个参数keep_prob: 设置神经元被选中的概率,在初始化时keep_prob是一个占位符, keep_prob = tf.placeholder(tf.float32) 。tensorflow在run时设置keep_prob具体的值,例如keep_prob: 0.5
第五个参数name:指定该操作的名字。
举例
dropout必须设置概率keep_prob,并且keep_prob也是一个占位符,跟输入是一样的
keep_prob = tf.placeholder(tf.float32)train的时候才是dropout起作用的时候,test的时候不应该让dropout起作用
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5})
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1}) 在 cnn 中运用的例子
with tf.variable_scope('layer9-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, 1024],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [1024], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train: fc1 = tf.nn.dropout(fc1, 0.5)S
sparse_softmax_cross_entropy_with_logits
sparse_softmax_cross_entropy_with_logits
tf.nn.sparse_softmax_cross_entropy_with_logits
sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
相当于合并了softmax和cross_entropy两步
说明
此函数大致与tf_nn_softmax_cross_entropy_with_logits的计算方式相同,
适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
但是在对于labels的处理上有不同之处,labels从shape来说此函数要求shape为[batch_size],
labels[i]是[0,num_classes)的一个索引, type为int32或int64,即labels限定了是一个一阶tensor,
并且取值范围只能在分类数之内,表示一个对象只能属于一个类别
参数
_sentinel:本质上是不用的参数,不用填
labels 的输入是稀疏表示的,是 [0,num_classes)中的一个数值,代表正确分类 。labels 的 shape为 [batch_size],即 有batch个数值
这个labels参数要注意,它的shape必须是[d_0, d_1, ..., d_{r-1}]'(而参数logits的shape是[d_0, d_1, ..., d_{r-1},num_classes]其中差别自行体会) 数据类型必须是int32或者int64,且在labels中的每个值必须是在[0,num_classes),否则在这个操作运行在cpu的时候将会出现exception,运行在GPU的时候将会返回’NaN’,而不是返回loss了,这个情况我遇到过,所以在看到输出的不是loss值而是‘NaN’时就应该仔细检查一下这个函数中的labels有没有符合条件。
logits:logits 是神经网络运行的结果(tensorflow神经网络中没有softmax层,而是在此方法会进行softmax运算),shape为[batch_size,num_classes],type为float32或float64
logits:这里注意shape和数据类型必须是float32和float64,一般很容易搞错,而tf.nn.softmax_cross_entropy_with_logits求 数据类型可以是float16 ,float32 or float64.
name:操作的名字,可填可不填
一般的使用
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y_, 1), logits=y)
cross_entropy_mean = tf.reduce_mean(cross_entropy)1 | import tensorflow as tf |
tf.nn.softmax_cross_entropy_with_logits
softmax_cross_entropy_with_logits(
_sentinel=None,
labels=None,
logits=None,
dim=-1,
name=None
)logits和labels的shape都是[batch_size, num_classes]
tf.nn.softmax_cross_entropy_with_logits 和 tf.nn.sparse_softmax_cross_entropy_with_logits 的异同
两方法的结果是相同的。sparse_softmax_cross_entropy_with_logits 直接用标签上计算交叉熵,而 softmax_cross_entropy_with_logits 是标签的onehot向量参与计算。softmax_cross_entropy_with_logits 的 labels 是 sparse_softmax_cross_entropy_with_logits 的 labels 的一个独热版本(one hot version)。
这个函数和tf.nn.softmax_cross_entropy_with_logits函数比较明显的区别在于它的参数labels的不同,这里的参数label是非稀疏表示的,比如表示一个3分类的一个样本的标签,稀疏表示的形式为[0,0,1]这个表示这个样本为第3个分类,而非稀疏表示就表示为2(因为从0开始算,0,1,2,就能表示三类),同理[0,1,0]就表示样本属于第二个分类,而其非稀疏表示为1。
tf.nn.sparse_softmax_cross_entropy_with_logits()比tf.nn.softmax_cross_entropy_with_logits多了一步将labels稀疏化的操作。因为深度学习中,图片一般是用非稀疏的标签的,所以用tf.nn.sparse_softmax_cross_entropy_with_logits()的频率比tf.nn.softmax_cross_entropy_with_logits高。
1 | import tensorflow as tf |
但是,有一点需要知道,就是输出值的数目需要和标签的 one-hot 编码位数一样,下面是举个例子
1 | import tensorflow as tf |
上面的代码可以正常输出,但是下面的就不行。
1 | import tensorflow as tf |
相关知识
归一化:
1、把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
2、把有量纲表达式变为无量纲表达式归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
One-Hot Encoding(独热编码)
One-Hot编码,又称为一位有效编码,主要是采用位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
解决了分类器不好处理属性数据的问题
在一定程度上也起到了扩充特征的作用softmax
tf.nn.softmax(
logits,
axis=None,
name=None,
dim=None
)这个函数的作用相当于:
softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), axis)1 | import tensorflow as tf |