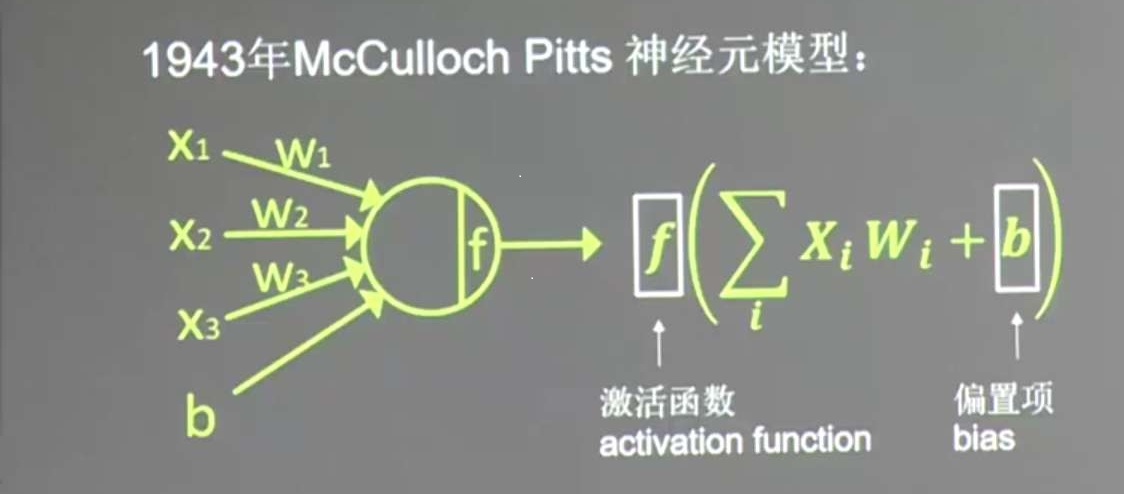
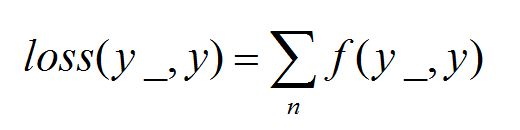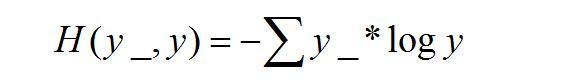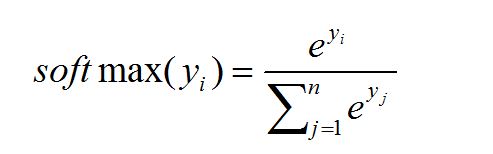#2 定义损失函数及反向传播方法 loss = tf.reduce_mean(tf.square(y - y_)) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#3 生成会话,训练 steps 轮 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)
# 训练模型 STEPS = 20000 for i in range(STEPS): start = (i * BATCH_SIZE) % 32 end = start + BATCH_SIZE sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) if i % 500 == 0: total_loss = sess.run(loss,feed_dict={x:X,y_:Y_}) print(sess.run(w1)) print("After %d training step(s),loss on all data is %g" % (i,total_loss))
# [[-0.80974597] # [ 1.4852903 ]] # After 0 training step(s),loss on all data is 0.655701 # [[-0.46074435] # [ 1.641878 ]] # After 500 training step(s),loss on all data is 0.35731 # [[-0.21939856] # [ 1.6984766 ]] # After 1000 training step(s),loss on all data is 0.232481 # [[-0.04415595] # [ 1.7003176 ]] # After 1500 training step(s),loss on all data is 0.170404 # [[0.08942621] # [1.673328 ]] # After 2000 training step(s),loss on all data is 0.133037 # [[0.19583555] # [1.6322677 ]] # After 2500 training step(s),loss on all data is 0.106939 # [[0.28375748] # [1.5854434 ]] # After 3000 training step(s),loss on all data is 0.0870619 # [[0.35848638] # [1.5374472 ]] # After 3500 training step(s),loss on all data is 0.0712709 # [[0.42332518] # [1.4907393 ]] # After 4000 training step(s),loss on all data is 0.0584907 # [[0.48040026] # [1.4465574 ]] # After 4500 training step(s),loss on all data is 0.0480653 # [[0.53113604] # [1.4054536 ]] # After 5000 training step(s),loss on all data is 0.0395331 # [[0.5765325] # [1.3675941]] # After 5500 training step(s),loss on all data is 0.0325409 # [[0.61732584] # [1.3329403 ]] # After 6000 training step(s),loss on all data is 0.0268078 # [[0.6540846] # [1.3013426]] # After 6500 training step(s),loss on all data is 0.0221059 # [[0.6872685] # [1.272602 ]] # After 7000 training step(s),loss on all data is 0.0182493 # [[0.71725976] # [1.2465005 ]] # After 7500 training step(s),loss on all data is 0.015086 # [[0.7443861] # [1.2228197]] # After 8000 training step(s),loss on all data is 0.0124914 # [[0.7689324] # [1.2013483]] # After 8500 training step(s),loss on all data is 0.0103631 # [[0.79115134] # [1.1818889 ]] # After 9000 training step(s),loss on all data is 0.00861742 # [[0.811267 ] # [1.1642567]] # After 9500 training step(s),loss on all data is 0.00718553 # [[0.8294814] # [1.1482829]] # After 10000 training step(s),loss on all data is 0.006011 # [[0.84597576] # [1.1338125 ]] # After 10500 training step(s),loss on all data is 0.00504758 # [[0.8609128] # [1.1207061]] # After 11000 training step(s),loss on all data is 0.00425734 # [[0.87444043] # [1.1088346 ]] # After 11500 training step(s),loss on all data is 0.00360914 # [[0.88669145] # [1.0980824 ]] # After 12000 training step(s),loss on all data is 0.00307745 # [[0.8977863] # [1.0883439]] # After 12500 training step(s),loss on all data is 0.00264134 # [[0.9078348] # [1.0795243]] # After 13000 training step(s),loss on all data is 0.00228362 # [[0.91693527] # [1.0715363 ]] # After 13500 training step(s),loss on all data is 0.00199021 # [[0.92517716] # [1.0643018 ]] # After 14000 training step(s),loss on all data is 0.00174954 # [[0.93264157] # [1.0577497 ]] # After 14500 training step(s),loss on all data is 0.00155213 # [[0.9394023] # [1.0518153]] # After 15000 training step(s),loss on all data is 0.00139019 # [[0.9455251] # [1.0464406]] # After 15500 training step(s),loss on all data is 0.00125737 # [[0.95107025] # [1.0415728 ]] # After 16000 training step(s),loss on all data is 0.00114842 # [[0.9560928] # [1.037164 ]] # After 16500 training step(s),loss on all data is 0.00105905 # [[0.96064115] # [1.0331714 ]] # After 17000 training step(s),loss on all data is 0.000985753 # [[0.96476096] # [1.0295546 ]] # After 17500 training step(s),loss on all data is 0.000925622 # [[0.9684917] # [1.0262802]] # After 18000 training step(s),loss on all data is 0.00087631 # [[0.9718707] # [1.0233142]] # After 18500 training step(s),loss on all data is 0.000835858 # [[0.974931 ] # [1.0206276]] # After 19000 training step(s),loss on all data is 0.000802676 # [[0.9777026] # [1.0181949]] # After 19500 training step(s),loss on all data is 0.000775461
结论
逻辑上我们可以得出,当销量和产量平齐的时候,企业能获得最大的利润,所以,我们可以看到参数慢慢趋近于 1,而 loss 也越来越小。
场景二 自定义损失函数
描述
还是接上一个例子,虽然均方误差能够使得产量和销量相平齐,但是无法使得利益最大化。
比如,预测多了,成本会增加,预测少了,利润会减少。
所以我们要自定义损失函数,公式如下:
在 tf 中,具体代码如下:
loss = tf.reduce_sum(tf.where(tf.greater(y,y_),(y - y_) * COST,(y_ - y) * PROFIT))
tf.where(tf.greater(y,y_) 相当于一个三元选择器 即 y > y_ ? ,如果式子条件成立则选择前面,如果不成立则选择后面
#3 生成会话,训练 steps 轮 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)
# 训练模型 STEPS = 20000 for i in range(STEPS): start = (i * BATCH_SIZE) % 32 end = start + BATCH_SIZE sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) if i % 500 == 0: total_loss = sess.run(loss,feed_dict={x:X,y_:Y_}) print(sess.run(w1)) print("After %d training step(s),loss on all data is %g" % (i,total_loss))
# [[-0.762993 ] # [ 1.5095658]] # After 0 training step(s),loss on all data is 178.826 # [[1.0235443] # [1.0463386]] # After 500 training step(s),loss on all data is 1.93054 # [[1.0174844] # [1.0406483]] # After 1000 training step(s),loss on all data is 1.92153 # [[1.0211805] # [1.0472497]] # After 1500 training step(s),loss on all data is 1.92689 # [[1.0179386] # [1.0412899]] # After 2000 training step(s),loss on all data is 1.91444 # [[1.0205938] # [1.0390677]] # After 2500 training step(s),loss on all data is 1.91977 # [[1.0242898] # [1.0456691]] # After 3000 training step(s),loss on all data is 1.92866 # [[1.01823 ] # [1.0399789]] # After 3500 training step(s),loss on all data is 1.91861 # [[1.021926 ] # [1.0465802]] # After 4000 training step(s),loss on all data is 1.92529 # [[1.0245812] # [1.044358 ]] # After 4500 training step(s),loss on all data is 1.92074 # [[1.0185213] # [1.0386678]] # After 5000 training step(s),loss on all data is 1.92279 # [[1.0245652] # [1.0446368]] # After 5500 training step(s),loss on all data is 1.92261 # [[1.0185053] # [1.0389466]] # After 6000 training step(s),loss on all data is 1.92151 # [[1.0222014] # [1.045548 ]] # After 6500 training step(s),loss on all data is 1.91924 # [[1.0161415] # [1.0398577]] # After 7000 training step(s),loss on all data is 1.93691 # [[1.0198376] # [1.0464591]] # After 7500 training step(s),loss on all data is 1.91587 # [[1.0224928] # [1.0442369]] # After 8000 training step(s),loss on all data is 1.91131 # [[1.0174738] # [1.0473702]] # After 8500 training step(s),loss on all data is 1.91249 # [[1.0222716] # [1.0383747]] # After 9000 training step(s),loss on all data is 1.92229 # [[1.0172527] # [1.041508 ]] # After 9500 training step(s),loss on all data is 1.91914 # [[1.0199078] # [1.0392858]] # After 10000 training step(s),loss on all data is 1.919 # [[1.0236039] # [1.0458871]] # After 10500 training step(s),loss on all data is 1.92736 # [[1.017544 ] # [1.0401969]] # After 11000 training step(s),loss on all data is 1.92332 # [[1.0212401] # [1.0467982]] # After 11500 training step(s),loss on all data is 1.92399 # [[1.0238953] # [1.044576 ]] # After 12000 training step(s),loss on all data is 1.91943 # [[1.0178354] # [1.0388858]] # After 12500 training step(s),loss on all data is 1.92749 # [[1.0215315] # [1.0454872]] # After 13000 training step(s),loss on all data is 1.91606 # [[1.0154716] # [1.039797 ]] # After 13500 training step(s),loss on all data is 1.94288 # [[1.0191677] # [1.0463983]] # After 14000 training step(s),loss on all data is 1.91269 # [[1.0162914] # [1.0427582]] # After 14500 training step(s),loss on all data is 1.92095 # [[1.0189465] # [1.040536 ]] # After 15000 training step(s),loss on all data is 1.91422 # [[1.0216017] # [1.0383139]] # After 15500 training step(s),loss on all data is 1.92261 # [[1.0252978] # [1.0449152]] # After 16000 training step(s),loss on all data is 1.92756 # [[1.0192379] # [1.039225 ]] # After 16500 training step(s),loss on all data is 1.91931 # [[1.022934 ] # [1.0458263]] # After 17000 training step(s),loss on all data is 1.92419 # [[1.0168741] # [1.0401361]] # After 17500 training step(s),loss on all data is 1.92929 # [[1.0205702] # [1.0467374]] # After 18000 training step(s),loss on all data is 1.92081 # [[1.0232253] # [1.0445153]] # After 18500 training step(s),loss on all data is 1.91626 # [[1.0171654] # [1.038825 ]] # After 19000 training step(s),loss on all data is 1.93347 # [[1.0208615] # [1.0454264]] # After 19500 training step(s),loss on all data is 1.91289
#3 生成会话,训练 steps 轮 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)
# 训练模型 STEPS = 20000 for i in range(STEPS): start = (i * BATCH_SIZE) % 32 end = start + BATCH_SIZE sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) if i % 500 == 0: total_loss = sess.run(loss,feed_dict={x:X,y_:Y_}) print(sess.run(w1)) print("After %d training step(s),loss on all data is %g" % (i,total_loss))
# [[-0.80594873] # [ 1.4873729 ]] # After 0 training step(s),loss on all data is 29.8745 # [[0.8732146] # [1.006204 ]] # After 500 training step(s),loss on all data is 2.38814 # [[0.9658064] # [0.9698208]] # After 1000 training step(s),loss on all data is 1.46394 # [[0.9645447] # [0.9682946]] # After 1500 training step(s),loss on all data is 1.46911 # [[0.9602475] # [0.9742084]] # After 2000 training step(s),loss on all data is 1.43915 # [[0.96100295] # [0.96993417]] # After 2500 training step(s),loss on all data is 1.45907 # [[0.9654102] # [0.9761159]] # After 3000 training step(s),loss on all data is 1.43333 # [[0.96414846] # [0.9745897 ]] # After 3500 training step(s),loss on all data is 1.43359 # [[0.95985126] # [0.9805035 ]] # After 4000 training step(s),loss on all data is 1.44526 # [[0.9636422] # [0.9687893]] # After 4500 training step(s),loss on all data is 1.46411 # [[0.959345 ] # [0.9747031]] # After 5000 training step(s),loss on all data is 1.44187 # [[0.9667877] # [0.9734448]] # After 5500 training step(s),loss on all data is 1.44656 # [[0.9641995] # [0.9676626]] # After 6000 training step(s),loss on all data is 1.4717 # [[0.9655712 ] # [0.98128426]] # After 6500 training step(s),loss on all data is 1.48756 # [[0.9653083] # [0.9817019]] # After 7000 training step(s),loss on all data is 1.48998 # [[0.9670821 ] # [0.97273576]] # After 7500 training step(s),loss on all data is 1.4512 # [[0.964802 ] # [0.9759015]] # After 8000 training step(s),loss on all data is 1.42806 # [[0.9658656] # [0.9805752]] # After 8500 training step(s),loss on all data is 1.48214 # [[0.9646039] # [0.979049 ]] # After 9000 training step(s),loss on all data is 1.45434 # [[0.96303403] # [0.9685749 ]] # After 9500 training step(s),loss on all data is 1.46374 # [[0.95873684] # [0.9744887 ]] # After 10000 training step(s),loss on all data is 1.44686 # [[0.9598004] # [0.9791624]] # After 10500 training step(s),loss on all data is 1.43406 # [[0.966935 ] # [0.9689562]] # After 11000 training step(s),loss on all data is 1.47155 # [[0.95929414] # [0.97336197]] # After 11500 training step(s),loss on all data is 1.4499 # [[0.96004957] # [0.9690877 ]] # After 12000 training step(s),loss on all data is 1.46982 # [[0.9600948 ] # [0.97845334]] # After 12500 training step(s),loss on all data is 1.43006 # [[0.96085024] # [0.9741791 ]] # After 13000 training step(s),loss on all data is 1.4356 # [[0.9649493 ] # [0.97141284]] # After 13500 training step(s),loss on all data is 1.45304 # [[0.96499455] # [0.98077846]] # After 14000 training step(s),loss on all data is 1.47699 # [[0.96373284] # [0.9792523 ]] # After 14500 training step(s),loss on all data is 1.4492 # [[0.962163 ] # [0.96877813]] # After 15000 training step(s),loss on all data is 1.46042 # [[0.9601911] # [0.9808918]] # After 15500 training step(s),loss on all data is 1.44943 # [[0.95892936] # [0.97936565]] # After 16000 training step(s),loss on all data is 1.43981 # [[0.9660639] # [0.9691594]] # After 16500 training step(s),loss on all data is 1.46822 # [[0.9604402 ] # [0.97081715]] # After 17000 training step(s),loss on all data is 1.45746 # [[0.96484745] # [0.97699887]] # After 17500 training step(s),loss on all data is 1.43351 # [[0.9642764 ] # [0.96846855]] # After 18000 training step(s),loss on all data is 1.46748 # [[0.9599792 ] # [0.97438234]] # After 18500 training step(s),loss on all data is 1.4398 # [[0.9630599] # [0.976308 ]] # After 19000 training step(s),loss on all data is 1.42141 # [[0.967159 ] # [0.97354174]] # After 19500 training step(s),loss on all data is 1.44697