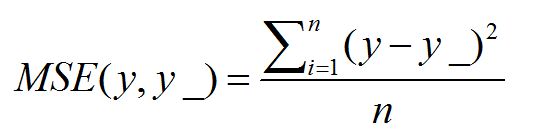1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
import tensorflow as tf
import numpy as np
BATCH_SIZE = 8
seed = 23455
rng = np.random.RandomState(seed)
X = rng.rand(32,2)
Y = [[int(X0 + X1 < 1)] for (X0,X1) in X]
x = tf.placeholder(tf.float32,shape=(None,2))
y_ = tf.placeholder(tf.float32,shape=(None,1))
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
loss = tf.reduce_mean(tf.square(y - y_))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
STEPS = 3000
for i in range(STEPS):
start = (i * BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
if i % 500 == 0:
total_loss = sess.run(loss,feed_dict={x:X,y_:Y})
print("After %d training step(s),loss on all data is %g" % (i,total_loss))
print(sess.run(w1))
print(sess.run(w2))
|