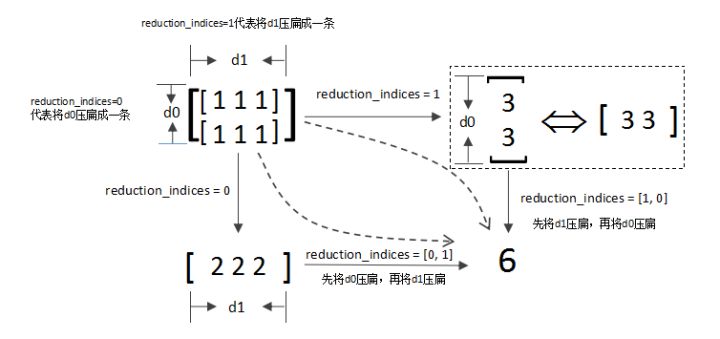
如题。
A add_to_collection tf.add_to_collection(‘list_name’, element):将元素element添加到列表list_name中
tf.get_collection(‘list_name’):返回名称为list_name的列表
tf.add_n(list):将列表元素相加并返回
1 2 3 4 5 6 import tensorflow as tftf.add_to_collection('losses' , tf.constant(2.2 )) tf.add_to_collection('losses' , tf.constant(3. )) with tf.Session() as sess: print(sess.run(tf.get_collection('losses' ))) print(sess.run(tf.add_n(tf.get_collection('losses' ))
结果:
[2.2, 3.0]
5.2
注意:
使用tf.add_n对列表元素进行相加时,列表内元素类型必须一致,否则会报错。all_variables 参照 trainable_variables
E exp() 1 2 3 4 5 6 7 8 import tensorflow as tfx = tf.constant([[1.0 ,2.0 ],[5.0 ,3.0 ]]) x_2 = tf.exp(x) with tf.Session() as sess: print(sess.run(x_2))
G get_variable tf.get_variable函数的使用 tf.get_variable函数
tf.constant_initializer:常量初始化函数
tf.random_normal_initializer:正态分布
tf.truncated_normal_initializer:截取的正态分布
tf.random_uniform_initializer:均匀分布
tf.zeros_initializer:全部是0
tf.ones_initializer:全是1
tf.uniform_unit_scaling_initializer:满足均匀分布,但不影响输出数量级的随机值1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import tensorflow as tf; import numpy as np; import matplotlib.pyplot as plt; a1 = tf.get_variable(name='a1' , shape=[2 ,3 ], initializer=tf.random_normal_initializer(mean=0 , stddev=1 )) a2 = tf.get_variable(name='a2' , shape=[1 ], initializer=tf.constant_initializer(1 )) a3 = tf.get_variable(name='a3' , shape=[2 ,3 ], initializer=tf.ones_initializer()) with tf.Session() as sess: sess.run(tf.initialize_all_variables()) print sess.run(a1) print sess.run(a2) print sess.run(a3) [[ 0.42299312 -0.25459203 -0.88605702 ] [ 0.22410156 1.34326422 -0.39722782 ]] [ 1. ] [[ 1. 1. 1. ] [ 1. 1. 1. ]]
注意:不同的变量之间不能有相同的名字,除非你定义了variable_scope,这样才可以有相同的名字。
M matmul 这是矩阵的相乘,相当于 numpy 的 dot
1 2 3 4 5 6 7 8 9 import tensorflow as tfmatrix1 = tf.constant([[3 ,3 ]]) matrix2 = tf.constant([[2 ],[2 ]]) product = tf.matmul(matrix1,matrix2) with tf.Session() as sess: result = sess.run(product) print(result)
N newaxis np.newaxis的功能是插入新维度,看下面的例子:
1 2 3 4 5 6 7 8 9 a=np.array([1 ,2 ,3 ,4 ,5 ]) b=a[np.newaxis,:] print a.shape,b.shape print a print b
1 2 3 4 5 6 7 8 9 10 11 12 a=np.array([1 ,2 ,3 ,4 ,5 ]) b=a[:,np.newaxis] print a.shape,b.shape print a print b
可以看出np.newaxis分别是在行或列上增加维度,原来是(6,)的数组,在行上增加维度变成(1,6)的二维数组,在列上增加维度变为(6,1)的二维数组
I initialize_all_variables 如果定义了变量,就必须先初始化。
with tf.Session() as sess:
sess.run(init)P placeholder() 这个函数相当于一个占位符,在 sess.run() 的时候通过 feed_dict 的方式,以键值对的方式传入参数
1 2 3 4 5 6 7 8 9 10 11 12 13 import tensorflow as tfinput1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32,[2 ,2 ]) input3 = tf.placeholder(tf.float32) output = tf.multiply(input1,input3) with tf.Session() as sess: print(sess.run(output,feed_dict={input1:[7. ],input3:[8. ]}))
R reduce_mean() tf.reduce_mean(input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None)
第一个参数input_tensor: 输入的待降维的tensor;
第二个参数axis: 指定的轴,如果不指定,则计算所有元素的均值;
第三个参数keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度;
第四个参数name: 操作的名称;
第五个参数 reduction_indices:在以前版本中用来指定轴,已弃用;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import tensorflow as tf x = [[1 ,2 ,3 ], [1 ,2 ,3 ]] xx = tf.cast(x,tf.float32) mean_all = tf.reduce_mean(xx, keep_dims=False ) mean_0 = tf.reduce_mean(xx, axis=0 , keep_dims=False ) mean_1 = tf.reduce_mean(xx, axis=1 , keep_dims=False ) with tf.Session() as sess: m_a,m_0,m_1 = sess.run([mean_all, mean_0, mean_1]) print m_a print m_0 print m_1 print m_a print m_0 print m_1
reduce_sum() reduce_sum(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None
)reduce_sum() 就是求和,由于求和的对象是tensor,所以是沿着tensor的某些维度求和。函数名中加了reduce是表示求和后会降维,当然可以通过设置参数来保证不降维,但是默认就是要降维的。
S square tf.square(x, name=None)
T trainable_variables() tf.trainable_variables返回的是需要训练的变量列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import tensorflow as tf; import numpy as np; import matplotlib.pyplot as plt; v = tf.Variable(tf.constant(0.0 , shape=[1 ], dtype=tf.float32), name='v' ) v1 = tf.Variable(tf.constant(5 , shape=[1 ], dtype=tf.float32), name='v1' ) global_step = tf.Variable(tf.constant(5 , shape=[1 ], dtype=tf.float32), name='global_step' , trainable=False ) ema = tf.train.ExponentialMovingAverage(0.99 , global_step) for ele1 in tf.trainable_variables(): print ele1.name for ele2 in tf.all_variables(): print ele2.name
输出:
v:0
v1:0
v:0
v1:0
global_step:0分析:
V Variable() tensorflow 就好像 java 一样,变量必须声明之后才是变量,如果不声明就不是 tensorflow 变量。。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import tensorflow as tfstate = tf.Variable(0 ,name='counter' ) print(state.name) one = tf.constant(1 ) new_value = tf.add(state , one) update = tf.assign(state,new_value) init = tf.initialize_all_variables() with tf.Session() as sess: sess.run(init) for _ in range(3 ): sess.run(update) print(sess.run(state))
variable_scope tensorflow: name_scope 和 variable_scope区别及理解 tensorflow里面name_scope, variable_scope等如何理解?
tensorflow中创建variable的2种方式: tf.Variable():只要使用该函数,一律创建新的variable,如果出现重名,变量名后面会自动加上后缀1,2….
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import tensorflow as tfwith tf.name_scope('cltdevelop): var_1 = tf.Variable(initial_value=[0], name=' var_1') var_2 = tf.Variable(initial_value=[0], name=' var_1') var_3 = tf.Variable(initial_value=[0], name=' var_1') print(var_1.name) print(var_2.name) print(var_3.name) cltdevelop/var_1:0 cltdevelop/var_1_1:0 cltdevelop/var_1_2:0
tf.get_variable():如果变量存在,则使用以前创建的变量,如果不存在,则新创建一个变量。
tensorflow中的两种作用域 命名域(name scope):通过tf.name_scope()来实现;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import tensorflow as tfwith tf.name_scope('cltdevelop' ): var_1 = tf.Variable(initial_value=[0 ], name='var_1' ) var_2 = tf.get_variable(name='var_2' , shape=[1 , ]) with tf.variable_scope('aaa' ): var_3 = tf.Variable(initial_value=[0 ], name='var_3' ) var_4 = tf.get_variable(name='var_4' , shape=[1 , ]) print(var_1.name) print(var_2.name) print(var_3.name) print(var_4.name) cltdevelop/var_1:0 var_2:0 aaa/var_3:0 aaa/var_4:0
tensorflow中变量共享机制的实现 在tensorflow中变量共享机制是通过tf.get_variable()和tf.variable_scope()两者搭配使用来实现的。如下代码所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 import tensorflow as tfwith tf.variable_scope('cltdevelop' ): var_1 = tf.get_variable('var_1' , shape=[1 , ]) with tf.variable_scope('cltdevelop' , reuse=True ): var_2 = tf.get_variable('var_1' , shape=[1 ,]) print(var_1.name) print(var_2.name) cltdevelop/var_1:0 cltdevelop/var_1:0
[注:]当 reuse 设置为 True 或者 tf.AUTO_REUSE 时,表示这个scope下的变量是重用的或者共享的,也说明这个变量以前就已经创建好了。但如果这个变量以前没有被创建过,则在tf.variable_scope下调用tf.get_variable创建这个变量会报错。如下:
1 2 3 4 5 import tensorflow as tfwith tf.variable_scope('cltdevelop' , reuse=True ): var_1 = tf.get_variable('var_1' , shape=[1 , ])
则上述代码会报错
ValueErrorL Variable cltdevelop/v1 doesnot exist, or was not created with tf.get_variable()如果使用tf.get_variable()创建变量,且没有设置共享变量,重名时会报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import tensorflow as tfwith tf.name_scope('name_scope_1' ): var1 = tf.get_variable(name='var1' , shape=[1 ], dtype=tf.float32) var2 = tf.get_variable(name='var1' , shape=[1 ], dtype=tf.float32) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print(var1.name, sess.run(var1)) print(var2.name, sess.run(var2))
所以要共享变量,需要使用tf.variable_scope()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import tensorflow as tfwith tf.variable_scope('variable_scope_y' ) as scope: var1 = tf.get_variable(name='var1' , shape=[1 ], dtype=tf.float32) scope.reuse_variables() var1_reuse = tf.get_variable(name='var1' ) var2 = tf.Variable(initial_value=[2. ], name='var2' , dtype=tf.float32) var2_reuse = tf.Variable(initial_value=[2. ], name='var2' , dtype=tf.float32) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print(var1.name, sess.run(var1)) print(var1_reuse.name, sess.run(var1_reuse)) print(var2.name, sess.run(var2)) print(var2_reuse.name, sess.run(var2_reuse))
也可以这样
1 2 3 4 5 6 with tf.variable_scope('foo' ) as foo_scope: v = tf.get_variable('v' , [1 ]) with tf.variable_scope('foo' , reuse=True ): v1 = tf.get_variable('v' ) assert v1 == v
或者这样:
1 2 3 4 5 6 with tf.variable_scope('foo' ) as foo_scope: v = tf.get_variable('v' , [1 ]) with tf.variable_scope(foo_scope, reuse=True ): v1 = tf.get_variable('v' ) assert v1 == v