K-均值聚类算法是一个无监督学习算法。
它将相似的对象都归到同一个簇中,有点像全自动分类。聚类算法几乎可以应用于所有对象。之所以称之为 K-均值聚类算法是因为它可以发现 K 个不同的簇,每个簇的中心采用簇中所含值的均值计算而成。
原理
先介绍一幅图:
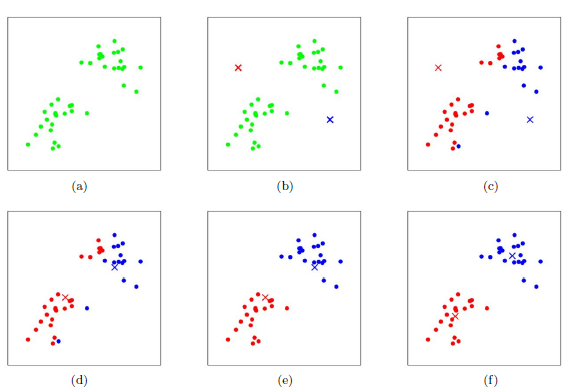
初始,数据没有分类,如第一幅。然后我们随机初始化两个 K 值,通过计算数据点离谁最近,就属于那个 K 分类。
距离计算:
dist = (a - k)^2
a 为数据点, k 为分类点每将数据点分到不同的类别,就重新计算 K 值,K 值的计算是由当前属于自己分类的数据点的平均値。计算出平均值后,重新分配 K 值,然后再次计算各数据点离 k 的距离。
重新分配数据集,最后当 K 值没有变化的时候,数据也就分类结束了。
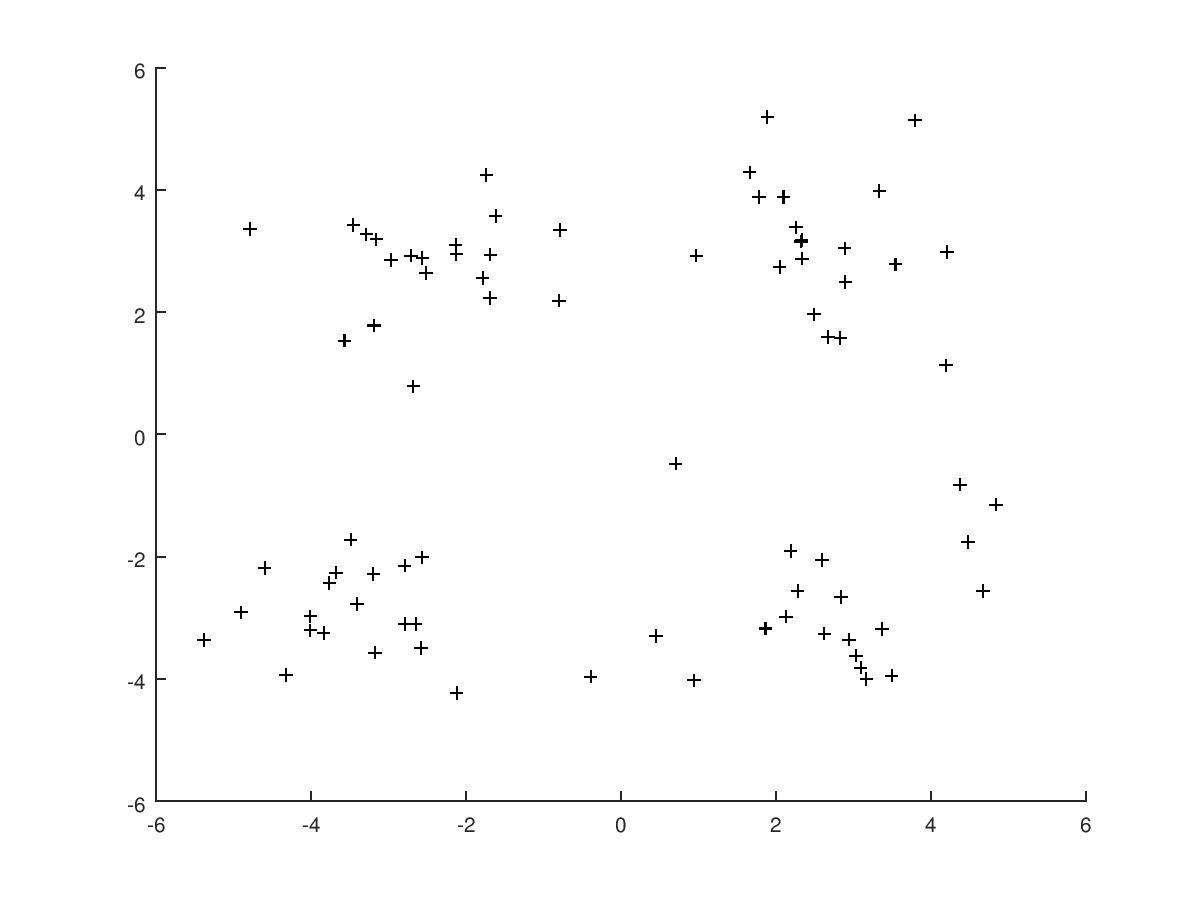
例子
首先我们先介绍一下数据,它在我的 github 中的 testSet.txt 文件中。
它的图像如下: