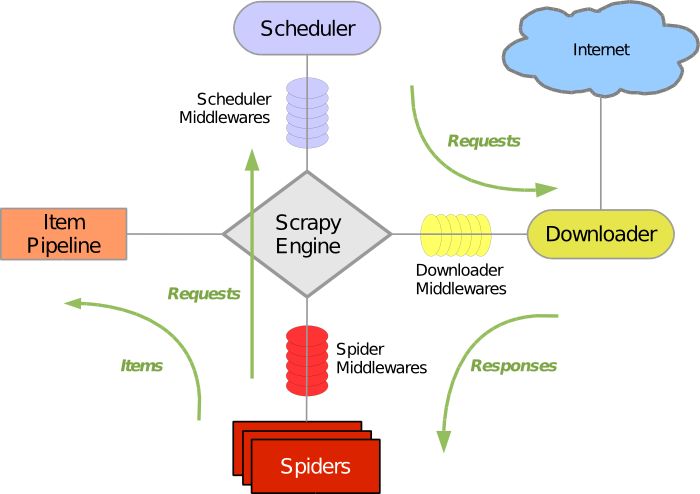
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| response.xpath()
排序从1开始
一般直接用F12探查的路径都是有误差的,如果是具体路径最好用查看源代码
但一般浏览器都有提供xpath的方法
/ 是选取子元素
// 选取后代元素
article 选取所有article元素的所有子节点
/article 选取根元素article
article/a 选取所有属于article的子元素的a元素
//div 选取所有div子元素(不论出现在任何地方)
article//div 选取所有属于article元素的后代div元素
//@class 选取所有名为class的属性
/article/div[1] 选取属于article子元素的第一个div元素
/article/div[last()] 选取属于article子元素的最后一个div元素
/article/div[last()-1]
//div[@lang] 选取所有拥有lang属性的div
//div[@lang='eng']
/div/* 选取属于div元素的所有子节点
//* 所有元素
//div[@*] 选取所有带属性的title元素
/div/a|//div/p 选取所有div元素的a和p元素
//span|//ul 选取文档中的span和div
article/div/p|//span 选取所有属于article的div的p元素和所有的span
如果只想获取内容,而不想要标签只需要在后面加入/text()
prise = "//*[@id='113180votetotal']/text()"
prise1 = response.xpath(prise).extract()[0]
提取出的内容str要想获取关键内容
只需要调用extract()方法,事实上在没调用这个方法前,得出的结构还可以用xpath继续调用
str.extract()
str = "//*[@id='post-113180']/div[1]/h1/text()"
h1 = response.xpath(str).extract()
如果某一个元素的一个属性含有多个名字,所以直接调用某一个名字可能出错
可以使用如下命令
//span[contains(@class,'vote')]
<div class='a b'>test</div>
xpath('//div[contains(@class,"a") and contains(@class,"b")]')
获取某一属性
post_url = response.xpath("//div[@id = 'archive']//div[@class = 'post-meta']//p//a[@class = 'archive-title']/@href")
上面的不需要在里面加text()函数
|