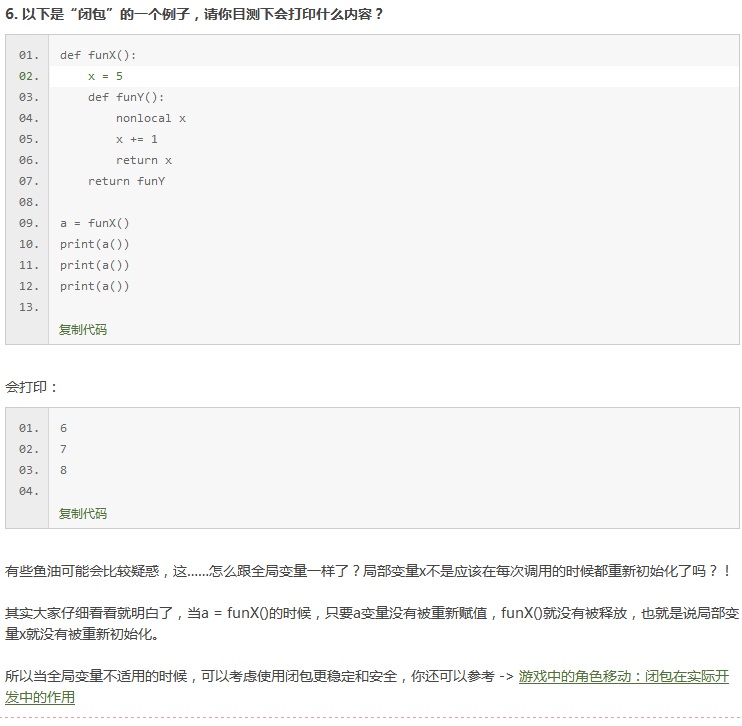
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
| 创建固定长度的列表
tmp = [0 for k in range(0,9)]
数组中可以添加不同数据类型的元素
向数组中添加有append()方法
但是这种方法只能支持一个独立参数
要是添加多个可以用extend()将参数作为一个列表去扩展列表末尾
extend()方法上传多个需要事先变成组
a = [2]
extend(["123","我爱你"]) 对
a = [2,"123","我爱你"]
extend("123","我爱你") 错
a = [1]
a.append([1,2])
a = [1,[1,2]]
a = [1,2,3]
b = [4,5,6]
a.append(b)
a
a = [1,2,3]
b = [4,5,6]
a.extend(b)
a
还有insert()方法添加元素
删除数组元素
remove() 必须制定内含元素
del 这是一个语句,不是内置函数,用法
mem = [1,2,3]
del mem[1]
mem = [1,3]
del mem 删除整个列表
pop() 默认删除最后一个元素,并返回
可以加上参数,指定位置
列表分片
对于具有序列结构的数据来说,切片操作的方法是:consequence[start_index: end_index: step]。
start_index:表示是第一个元素对象,正索引位置默认为0;负索引位置默认为 -len(consequence)
end_index:表示是最后一个元素对象,正索引位置默认为 len(consequence)-1;负索引位置默认为 -1。
step:表示取值的步长,默认为1,步长值不能为0。
[注意]对于序列结构数据来说,索引和步长都具有正负两个值,分别表示左右两个方向取值。索引的正方向从左往右取值,起始位置为0;负方向从右往左取值,起始位置为-1。因此任意一个序列结构数据的索引范围为 -len(consequence) 到 len(consequence)-1 范围内的连续整数。
mem = [1,2,3,4]
mem[1:3] 输出2,3
mem[:]获得一个列表的拷贝
mem1 = mem[:] 是完全拷贝,而不是地址指向,改变任意一个都不会影响另一个
copy() 的最后和 [:] 结果一样
列表可以直接拼接
mem + mem1
in的用法
123 in mem 如果存在会返回true
123 not in mem
mem = [1,2,["li"],3]
li in mem 返回false
li in mem[2] 返回true
列表也可以用乘法
mem = [1,2]
mem*=2
mem = [1,2,1,2]
count()的用法
mem = [1,1,2,3,1,4]
mem.count(1) 是3
index()返回参数在列表中的位置
有三个参数 第一个为元素,二三为范围
reverse()
将列表进行翻转
sort()
三个参数,第一个为指定算法,第二个不说,第三个为reverse如果指定为true,将翻转拍,从大到小
sort(reverse = true)
列表推导式又叫列表解析,用来动态创建列表
形式:
[有关A的表达式 for A in B] 能写成很复杂的式子
[x*x for x in range(3)]
[0,1,4,9]
dataSet = [
[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']
]
for i in range(len(dataSet[0]) - 1):
data = [example[i] for example in dataSet]
print(data)
|